

안녕하세요. 이번 글에서는 여러 정렬 알고리즘의 시간 복잡도를 증명해보겠습니다.
혹시 자료구조를 배우시는 분들이 계시다면, 시험볼 때 참고하시면 좋을 것 같습니다.
이 글은 $\LaTeX$ 문법이 잔뜩 적용되어 있어서, MathJax 스킨이 적용되어야 편하게 보인답니다.
혹시 Tistory 모바일 앱이나, 혹은 모바일 페이지 주소(nx006.tistory.com/m/67)로 접속이 되었을 경우, 인터넷 브라우저(Tistory 앱 X)에서 여기 주소로 다시 접속해주세요: https://nx006.tistory.com/67
정렬 알고리즘의 종류
이번 글은 정렬 알고리즘의 종류에 대해서 다루는 글은 아닙니다. 여기서는 간략하게 소개만 하고 넘어가겠습니다.
가장 대중적으로 많이 사용되는 정렬 알고리즘은 시간 복잡도에 따라서 크게 두 가지로 나뉩니다.
- 구현이 간단하나 시간 복잡도가 $O(n^2)$인 알고리즘
- 구현이 복잡하나 시간 복잡도가 $O(n\log n)$인 알고리즘
$O(n^2)$ 알고리즘의 경우 대표적으로 삽입 정렬이 있고, $O(n\log n)$인 알고리즘의 경우 대표적으로 힙 정렬(Heap Sort), 합병 정렬(Merge Sort), 퀵 정렬(Quick Sort)이 있습니다.
- 힙 정렬은 힙(Heap) 자료구조를 이용하는 정렬 알고리즘입니다.
- 합병 정렬은 파티셔닝 기술을 이용해서 정렬하고자 하는 대상을 분할한 후, 이를 다시 합치는 과정을 통해서 정렬을 수행합니다.
- 퀵 정렬은 피벗(Pivot)을 이용하는 알고리즘으로, 정렬의 기준점이 되는 피벗을 이리저리 옮겨가는 과정을 통해서 정렬을 수행합니다.
알고리즘 별 시간 복잡도 증명하기
글의 핵심인 알고리즘 별 시간 복잡도를 증명해보겠습니다.
증명해보고자 하는 주요한 알고리즘은 삽입 정렬, 퀵 정렬, 합병 정렬, 힙 정렬입니다.
이중에서 가장 중요한 알고리즘은 퀵 정렬입니다. 컴퓨터공학과 학생이고 자료구조 기말 시험을 치르러 간다면, 다른 정렬 알고리즘은 놓쳐도 퀵 정렬은 전부 외우고 가는 것이 좋습니다. 그렇기에 이 글에서도 퀵 정렬에 대해서만 자세히 다루고, 나머지 정렬 알고리즘은 간단하게만 다루고 넘어가겠습니다.
삽입 정렬(Insertion Sort)
우선 가장 쉬운 삽입 정렬(Insertion Sort)의 시간 복잡도에 대해서 증명해보겠습니다.
삽입 정렬은 구현이 단순하지만 시간 복잡도가 $O(n^2)$인 알고리즘입니다.
def insertion_sort(arr):
for i in range(1, len(arr)):
key = arr[i]
j = i - 1
while j >= 0 and key < arr[j]:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key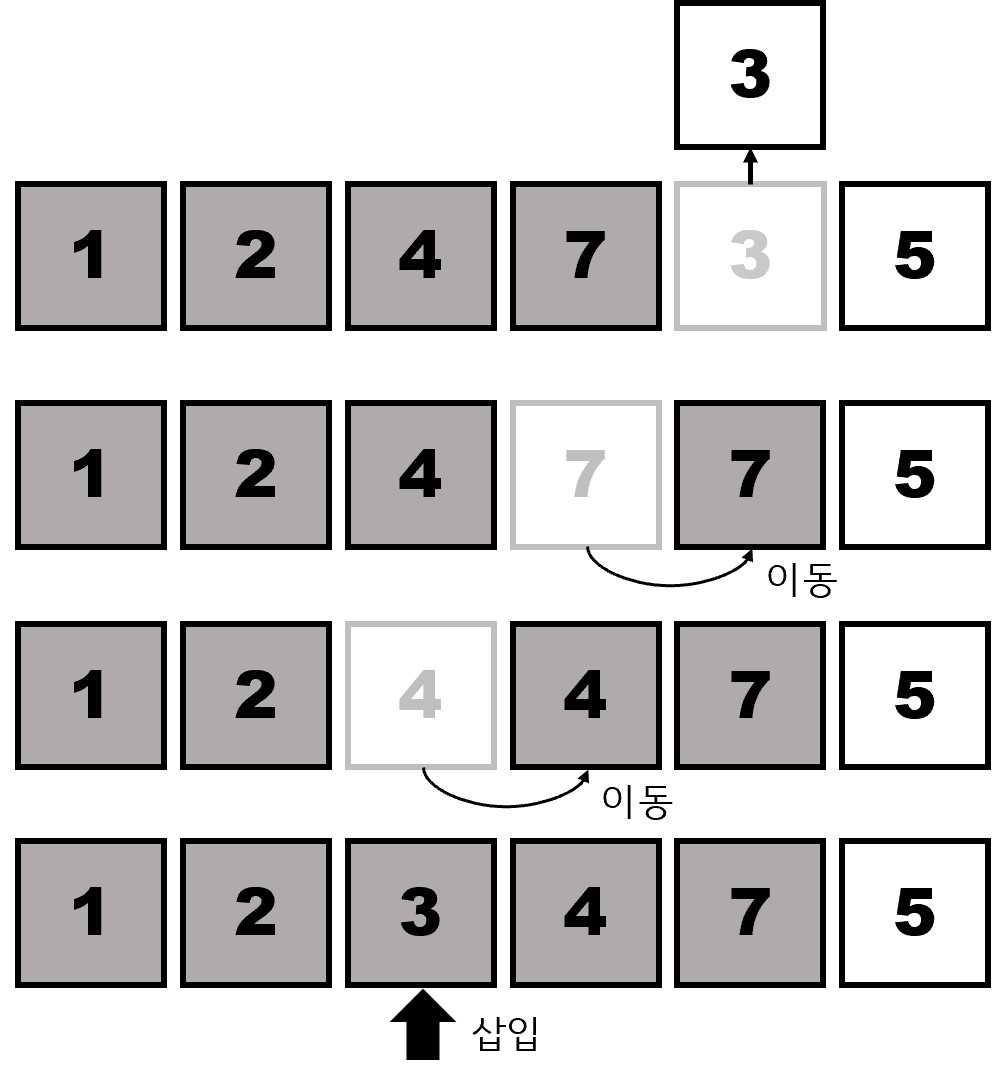
우선 시간 복잡도를 증명할 때 먼저 세 가지 시나리오로 상황을 가정하고 각각 증명할 수 있어야 합니다.
- 최악의 경우(Worst Case): 알고리즘이 수행될 때, 시간이 가장 오래 걸리는 최악의 시나리오를 가정합니다. 흔히 시간 복잡도를 말한다면 최악의 경우 시간 복잡도(Worst Case Time Complexity)를 의미합니다.
- 최선의 경우(Best Case): 알고리즘이 수행될 때 가장 이상적인 시나리오를 가정합니다. 일반적으로 시간 복잡도를 이야기할 때 최선의 경우는 고려하지 않습니다.
- 평균적인 경우(Average Case): 일반적인 경우에 알고리즘이 수행될 때, 평균적으로 어느 정도의 시간이 걸릴 지를 고려합니다.
또한, 시간 복잡도를 계산할 때 가장 중요하게 생각해보아야 하는 것은 ‘비교’와 ‘이동’ 연산입니다.
최악의 경우
삽입 정렬은 배열의 각 요소를 이미 정렬된 부분 배열에 올바른 위치에 '삽입'하는 방식으로 작동합니다.
삽입 정렬에서의 최악의 경우는 배열이 역순으로 정렬되어 있을 때입니다. 배열이 역순으로 정렬되어 있을 때, 개별 요소를 이미 정렬된 앞 단의 부분까지 이동시켜야 합니다. 즉 $i$ 번째 반복에서 $i$ 번의 비교와 이동 연산이 수행됩니다.
따라서 최악의 경우 삽입 정렬은 $\sum\limits_{i=1}^{n-1}i=1+2+\cdots+(n-1)=\cfrac{n(n-1)}{2}$ 의 이동 연산을 수행하게 됩니다. 따라서 최악의 경우 시간 복잡도는 $O(n^2)$ 입니다.
최선의 경우
최선의 경우는 배열이 이미 정렬이 된 상태입니다. 이 경우에는 $n-1$ 번의 비교 연산만 선형적으로 일어나게 됩니다. 이동은 필요 없습니다. 따라서 최선의 경우 시간 복잡도는 $O(n)$입니다.
평균적인 경우
평균적인 경우에 각 새로운 원소가 배열의 정렬된 부분의 중앙으로 가게 될 것입니다. 이 경우에도 $O(n^2)$의 시간이 필요하게 됩니다.
평균적이 경우의 시간 복잡도를 정확히 증명하려면 확률과 통계의 수학적인 기술이 필요해서, 일반적으로 1, 2학년 수준의 자료구조와 프로그래밍 과목에서는 다루지 않습니다. 그러나 필요하다면 아래의 흐름대로 평균적인 경우를 증명할 수 있습니다.
- 비교 횟수의 기댓값 구하기
- 각 원소가 $n$개의 배열에서 고르게 분포되어 있을 때(evenly distributed), 평균적으로는 중간 어딘가에 위치합니다. 각 $i$ 번째 원소를 정렬된 배열에 새로 삽입할 때 $\cfrac{i}{2}$ 번의 비교 연산이 필요함을 보일 수 있습니다.
- 전체 비교 횟수의 합$\cfrac{1}{2}+\cfrac{2}{2}+\cdots+\cfrac{n}{2}=\cfrac{1}{2}\left(1+2+\cdots+n \right)=\cfrac{n(n+1)}{4}$
- 비교 횟수의 기대값을 이용하면, 전체 비교 횟수의 합은 다음과 같이 됩니다:
- 위 식을 Big-O notation으로 나타내면 $O(n^2)$이 됩니다.
엄밀한 수학적 증명이 필요하다면 따로 찾아보는 게 좋을 것 같습니다.
퀵 정렬(Quick Sort)
가장 중요한 알고리즘입니다. 시험을 본다면, 다른 알고리즘은 몰라도 퀵 정렬은 외우고 가시는 게 좋습니다.
퀵 정렬은 시간 복잡도가 $O(n\log n)$입니다. 분할 정복(Divide and Conquer) 방법을 사용해서 정렬을 수행합니다. 정렬의 기준이 되는 피벗을 옮겨가면서 정렬을 수행합니다.
def quicksort(arr, low, high):
if low < high:
pivot_index = partition(arr, low, high)
quicksort(arr, low, pivot_index)
quicksort(arr, pivot_index + 1, high)
def partition(arr, low, high):
pivot = arr[low]
left = low + 1
right = high
done = False
while not done:
while left <= right and arr[left] <= pivot:
left = left + 1
while arr[right] >= pivot and right >=left:
right = right -1
if right < left:
done= True
else:
arr[left], arr[right] = arr[right], arr[left]
arr[low], arr[right] = arr[right], arr[low]
return right참고로 피벗을 정할 때 어떻게 정하느냐에 따라서 퀵 정렬 알고리즘의 성능 역시 크게 달라지게 됩니다. 그냥 단순히 피벗을 서브 리스트의 맨 왼쪽 원소로 선택하는 경우 최악의 경우 $O(n^2)$의 시간 복잡도가 나오게 되는데, 선택 과정에 변형을 주어 Median 방식을 선택할 경우 최악의 경우의 시간 복잡도를 방지할 수 있습니다. 그뿐만 아니라 실제 성능 역시 올라가게 됩니다.
그러나 이번 글에서는 이 과정에 대해서는 다루지 않겠습니다.
참고로 퀵 정렬에서만 시간 복잡도를 이야기할 때 최악의 경우가 아닌 평균적인 경우를 이야기합니다. 최악의 경우가 발생될 확률은 인위적으로 만들지 않는 이상 거의 0에 수렴하기에, 최악의 경우를 따지는 건 큰 의미가 없습니다.
퀵 정렬의 핵심은 Divide and Conquer, 즉 어떻게 원래의 배열을 잘게 쪼개서 서브 리스트로 만들 것이냐입니다.
평균적인 경우
가장 기본적인 방식은, quicksort가 재귀 함수로 이루어져 있으므로, 다음 식을 유도해나가면 됩니다.
$$
\begin{aligned}
T(n) & \leq cn +2T\left(\cfrac{n}{2}\right) \text{(for some constant c)} \\
& \leq cn+2\left(\cfrac{cn}{2}+2T\left(\cfrac{n}{4}\right)\right) \\
& \leq 2cn +4T\left(\cfrac{n}{4}\right) \\
& \vdots \\
& \leq cn\log_2 n + nT(1)=O(n\log_2 n)
\end{aligned}
$$
W.T.S(What to Show): $T_{avg}(n)$을 퀵 정렬이 원소를 정렬하는데 걸리는 예상 시간(expected time, 혹은 기댓값)이라 합니다. $n\leq2$에 대해서 $T_{avg}(n)\leq kn\ln n$ 을 만족하는 $k$가 존재함을 보이시오.
증명:
quicksort(arr, 1, n) 호출 시, 피벗이 $j$ 위치에 놓이게 된다고 가정합니다. 이때 크기가 각각 $j-1, n-j$인 두 서브 리스트를 정렬하는 문제로 나눌 수 있습니다. 각각의 서브리스트에 대해서 정렬 expected time은 각각 $T_{avg}(j-1)$, $T_{avg}(n-j)$ 입니다.
함수의 나머지는 어떤 상수 c에 대해서 최대 $cn$의 시간이 걸립니다. $j$가 $1$에서부터 $n$까지의 범위에서 똑같은 확률로 임의의 값을 취하기 때문에, $n\geq 2$ 에 대해서 다음 식을 얻습니다.
eq. 1:
$$
T_{avg}(n)\leq cn + \cfrac{1}{n}\sum\limits_{j=1}^{n}{(T_{avg}(j-1)+T_{avg}(n-j))} = cn+\cfrac{2}{n}\sum\limits_{j=0}^{n-1}{T_{avg}(j)}
$$
임의의 상수 b에 대해서 $T_{avg}(0)\leq b$ 와 $T_{avg}(1)\leq b$ 라고 가정한다면 $T_{avg}(0)+T_{avg}(1)\leq2b$ 입니다.
이제 우리는 $n\geq 2$ 이고 $k=2(b+c)$일 때 $T_{avg}(n)\leq kn\ln n$ 을 보일 것입니다.
이 과정에서 우리는 n에 대해서 수학적 귀납법을 사용합니다.
- Induction base: $n=2$ 에 대해서 eq. 1에 의해서 $T_{avg}(2)\leq 2c + 2b \leq kn\log_{e}{2}$
- Induction hypothesis: $1\leq n < m$에 대해 $T_{avg}(n) \leq kn\ln n$ 이라고 가정
- Induction step:
eq. 1과 induction hypothesis(귀납 가정)에 의해서, 아래 식을 얻을 수 있습니다.
eq. 2:
\[
\begin{aligned}
T_{\text{avg}}(m) & \leq cm + \cfrac{4b}{m} + \cfrac{2}{m} \sum\limits_{j=2}^{m-1} T_{\text{avg}}(j) \\
& \leq cm + \cfrac{4b}{m} + \cfrac{2k}{m} \sum\limits_{j=2}^{m-1} j\ln j
\end{aligned}
\]
이때 $j\ln j$가 $j$에 대해서 증가 함수이기 때문에, eq. 2에서 아래 식을 유도할 수 있습니다.
\[
\begin{aligned}
T_{\text{avg}}(m) & \leq cm+\cfrac{4b}{m}+\cfrac{2k}{m}\int_{2}^{m} x\ln x \,dx \\
& = cm+\cfrac{4b}{m}+\cfrac{2k}{m}\overbrace{\left(\cfrac{m^2\ln m}{2}-\cfrac{m^2}{4}\right)}^{\text{use partial integral}} \\
& = cm + \cfrac{4b}{m}+km\ln m - \cfrac{km}{2} \\
& \leq km\ln m \text{, for } m\geq 2
\end{aligned}
\]
따라서 $T_{\text{avg}}(n) \leq kn\ln n$ 이므로 $O(n\log n)$으로 나타낼 수 있습니다.
위의 유도 과정에서 $\int_{2}^{m} x\ln x \,dx$의 적분이 왜 $\frac{m^2\ln m}{2}-\frac{m^2}{4}$ 로 유도되는 지 의문이 드신다면, 이는 Partial Integral(부분 적분)을 사용한 것입니다. 고등학교, 혹은 대학수학(1) 등의 과목에서 Partial을 배우지 않았다면, 찾아보시기 바랍니다(도표 적분이라고도 합니다).
최선의 경우
가정 : 배열 안의 모든 데이터는 무작위로 배치되어 있다고 가정합니다. 즉, $n$개의 데이터를 대상으로 각 partition이 일어날 때 선택된 pivot에 대해 pivot보다 작은 데이터가 0개, 1개, …, $n-1$개 있을 확률이 모두 $\cfrac{1}{n}$이라 합니다.
$n$개의 원소인 배열을 정렬할 때 걸리는 수행 시간을 $T(n)$이라 합니다.
재귀 호출이 진행되기 전에 비교 연산을 수행할 때 걸리는 시간을 S(n)이라 합니다. 단, Quick Sort는 $S(n) = n$임이 성립합니다.
곧 quicksort에서는 다음이 성립합니다. 식(1):
$$
T(n)=\cfrac{2{T(0)+...+T(n-1)}}{n}+(n-1)
$$
(맨 마지막에 $S(n)=n$이 아닌 $(n-1)$이 오는 이유는, 원소가 한 개 있는 경우는 비교 연산이 의미가 없으므로 하나를 제외했기 때문입니다. 큰 신경 안 써도 됩니다.)
한편, $n=0$, $n=1$일 때는 정렬할 필요가 없으므로, $T(0)=T(1)=0$ 입니다.
위 식을 정리하면 식(2):
$$
nT(n)=2{T(0)+...+T(n-2)+T(n-1)}+n(n-1)
$$
한편 n-1에 대해 식(3):
$$
(n-1)T(n-1)=2{T(0)+...+T(n-2)}+(n-1)(n-2)
$$
식(2)와 식(3)을 빼면 식(4):
$$
nT(n)-(n-1)T(n-1)=2T(n-1)+2(n-1)
$$
위를 $nT(n)$에 관해 정리하면($(n-1)T(n-1)$을 우항으로 넘기면)
$$
nT(n)=(n+1)T(n-1)+2(n-1)
$$
n(n+1)으로 위 식을 나눕시다.
$$
\begin{aligned}
\cfrac{T(n)}{n+1}&=\cfrac{T(n-1)}{n}+\cfrac{2(n-1)}{n(n+1)}\\
&=\cfrac{T(n-1)}{n}+2(n-1) \left( \cfrac{1}{n}-\cfrac{1}{n+1}\right)\\
&=\cfrac{T(n-1)}{n}+\cfrac{2(n-1)}{n}-\cfrac{2(n-1)}{n+1}, \left(\because\frac{1}{n(n+1)}=\cfrac{1}{n}-\cfrac{1}{n+1}\right)
\end{aligned}
$$
이때 $\cfrac{B-A}{AB} = \cfrac{1}{A}-\cfrac{1}{B}$ 를 이용해서 식을 전개한 것입니다. 헷갈리지 않으시길 바랍니다.
같은 방식으로, $\cfrac{T(n-1)}{n}$ 을 다음과 같이 표현할 수 있습니다:
$\cfrac{T(n-1)}{n}=\cfrac{T(n-2)}{n-1}+\cfrac{2(n-2)}{n-1}-\cfrac{2(n-2)}{n}$
그러면 위의 수식을 다음과 같이 바꿔 쓸 수 있습니다:
$$
\cfrac{T(n)}{n+1}=\cfrac{T(n-2)}{n-1}+\cfrac{2(n-2)}{n-1}-\cfrac{2(n-2)}{n}+\cfrac{2(n-1)}{n}-\cfrac{2(n-1)}{n+1}
$$
한편 또다시 $\cfrac{T(n-2)}{n-1}=\cfrac{T(n-3)}{n-2}+\cfrac{2(n-3)}{n-2}-\cfrac{2(n-3)}{n-1}$에 대해 위 식을 다시 정리하면
$$
\cfrac{T(n)}{n+1}=\cfrac{T(n-3)}{n-2}+\cfrac{2(n-3)}{n-2}-\cfrac{2(n-3)}{n-1}+\cfrac{2(n-2)}{n-1}-\cfrac{2(n-2)}{n}+\cfrac{2(n-1)}{n}-\cfrac{2(n-1)}{n+1}
$$
이 됩니다.
계속해서 정리하면:
$$
\cfrac{T(n)}{n+1}=\cfrac{T(n-k)}{n-k+1}+2\left(\cfrac{1}{n-k+1}+...+\cfrac{1}{n}\right)-\cfrac{2(n-1)}{n+1}, (k\in\mathbb{N}\cap[1,n-1])
$$
$k=n-1$ 일 때:
\[\cfrac{T(n)}{n+1} = \cancelto{0}{\cfrac{T(1)}{2}} + \cfrac{2}{2} + \cfrac{2}{3} + \cdots + \cfrac{2}{n} - \cfrac{2(n-1)}{n+1} = \cancelto{0}{\cfrac{T(1)}{2}} + 2\left(\cfrac{1}{2} + \cdots + \cfrac{1}{n}\right) - \cancelto{c=2}{\cfrac{2(n-1)}{n+1}}
\]
\[
\because\lim_{n\to\infty}\cfrac{2(n-1)}{(n+1)}=2, T(1)=0\Longrightarrow\therefore \cfrac{T(n)}{n+1}\approx 2\left(\cfrac{1}{2}+...+\cfrac{1}{n}\right)
\]
한편 $2\left(\cfrac{1}{2}+...+\cfrac{1}{n}\right)$에 대해 $y=\cfrac{1}{x}(x\in\mathbb{R})$을 그래프로 표현하면 아래 그림과 같이 표현할 수 있습니다.
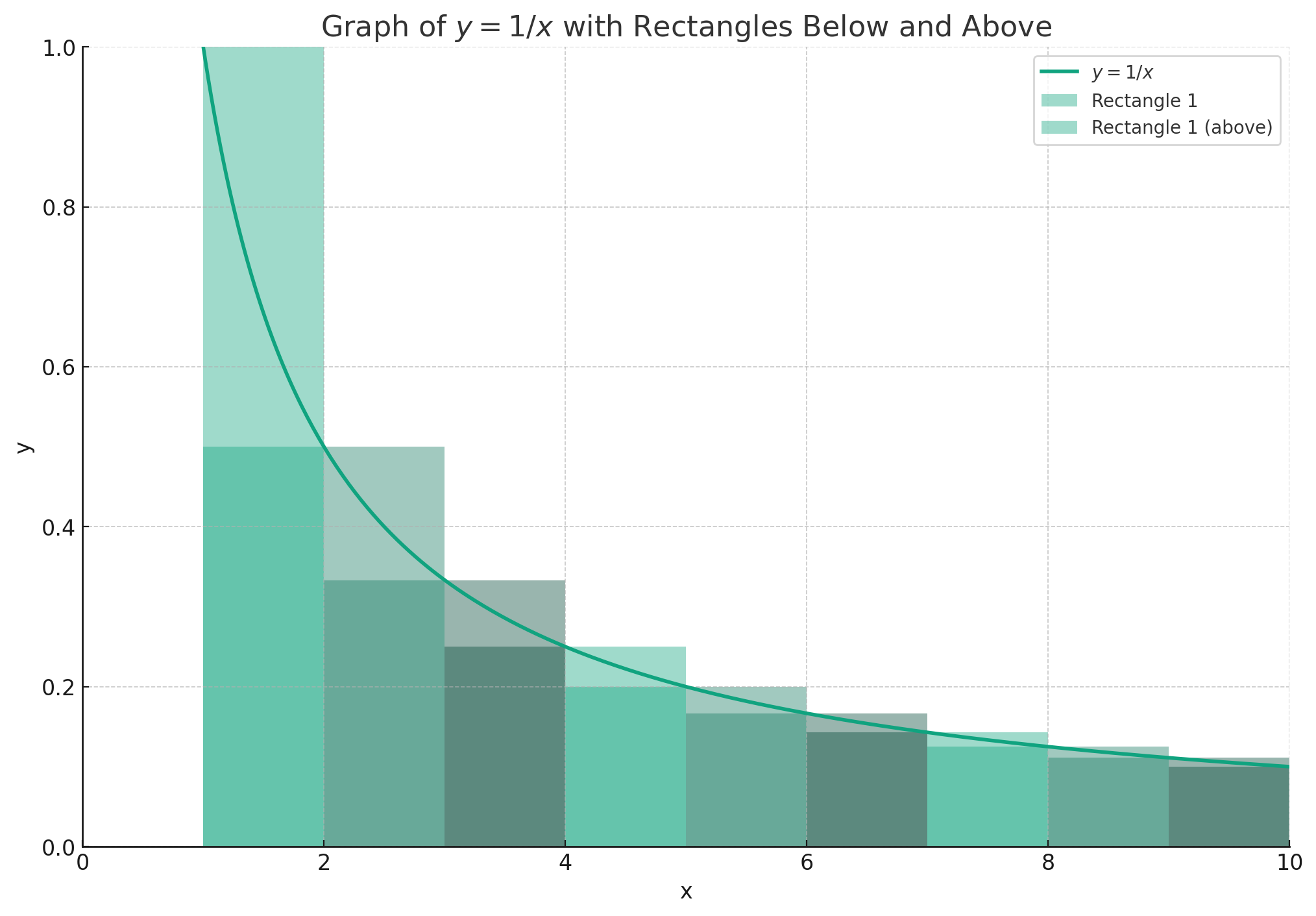
각각 직사각형이 $(n, f(n))$, $(n, f(n+1))$인 경우를 따로 따로 나누어서 분석해봅시다 (구분구적법 쓰는 거 맞습니다).
- 높이가 $f(n)$인 직사각형

위 그림에서 직사각형들의 넓이의 합은 $\left(\cfrac{1}{2}+...+\cfrac{1}{n}\right)$입니다. 이때 직사각형 넓이의 합이 $x=2$부터 $x=n+1$까지 y의 적분값보다 크므로 아래 식을 구할 수 있답니다:
$$
\left(\cfrac{1}{2}+...+\cfrac{1}{n}\right)=\sum_{k=2}^{n+1}{\cfrac{1}{k}}>\int_{2}^{n+1}{\frac{1}{x}dx}=\ln{(n+1)}-\ln{2}
$$
- 높이가 $f(n+1)$인 직사각형

곧 직사각형 넓이의 합이 $x=1$부터 $x=n$까지 함수 $y$의 적분값보다 작으므로 아래 식이 성립합니다:
$$
\left(\cfrac{1}{2}+...+\cfrac{1}{n}\right)<\int_{1}^{n}{\frac{1}{x}dx}=\ln{(n)}-\cancelto{0}{\ln{1}}
$$
따라서 압축 정리(Squeeze theorem, 혹은 샌드위치 정리)에 의해서 다음이 성립한답니다:
$$
\ln{(n+1)}-\ln{2}<\left(\cfrac{1}{2}+...+\cfrac{1}{n}\right)<\ln{(n)}
$$
$$
\sum_{k=2}^{n+1}{\cfrac{1}{k}}=\ln{n}
$$
곧 $\cfrac{T(n)}{n+1}$은 $2\ln{n}$ 꼴이므로
\[
\begin{aligned}
T(n) &= 2(n+1)(\ln n) \\
& = \cfrac{2}{\log_2 e} (n+1) \log_2 n \\
& \Longleftrightarrow T(n) = O(n \log_2 n)
\end{aligned}
\]
이렇게 해서 최선의 경우 시간 복잡도를 구할 수 있습니다.
최악의 경우
최악의 경우의 시간 복잡도는 다음 가정을 해서 구합니다.
가정 : $n$개의 데이터에 대해 매번 pivot이 선택될 때마다, 해당 pivot의 우선순위가 가장 높다고 합니다.
위 가정은 Pivot이 매번 맨 왼쪽에 가있어서, 서브 리스트로 Divide and conquer가 일어나지 않도록 막는 역할을 합니다.

이 경우 partition이 일어나지 않으므로, 매 n회의 데이터에 대해 n회 partition이 일어나고, 각 partition마다 $S(n)=n$회의 비교연산이 일어나므로
\begin{aligned}
T(n) &= n+(n-1)+(n-2)+(n-3)+\ldots+2 \\
& = \sum_{k=1}^{n}{k}-1 \\
& = \cfrac{n(n+1)}{2}-1
\end{aligned}
$$
\therefore T(n)=O(n^2)
$$
이렇게 보일 수 있습니다.
합병 정렬(Merge Sort)
Merge Sort는 Quick Sort와 다르게 최선, 최악, 평균의 시간 복잡도가 모두 동일합니다.
합병 정렬은 다음 순서대로 진행됩니다.
- 분할: 리스트를 두 서브 리스트로 분할합니다. 이때는 단순 분할이므로 상수 시간인 $O(1)$의 시간이 소요됩니다.
- 정복: 두 개의 서브 리스트를 정복합니다. 이때 시간 복잡도는 재귀적으로 계산되며, 각 서브 리스트에 대해서의 합병 정렬 시간 복잡도의 SUM입니다.
- 합병: 두 개의 서브 리스트를 다시 합칩니다. 이때는 N개 원소에 대해서 단순히 순회하는 과정을 거치므로 $O(n)$입니다.
n개 원소를 정렬하는데 걸리는 시간을 $T(n)$이라 해봅시다. $T(n)$을 다음과 같이 나타낼 수 있습니다.
$$
\begin{aligned}
T(n)&=O(1)+2T\left(\cfrac{1}{2}\right)+O(n) +O(1) \\ &= 2T\left(\cfrac{1}{2}\right)+O(n)
\end{aligned}
$$
이제, 각 부분 배열을 또다시 두 개의 서브 리스트로 나누어 봅시다. 이때 나누어진 서브 리스트의 크기는 1보다는 커야 합니다.
$$
\begin{aligned}
\forall c\in\mathbb{R}, T(n) & =2\left(2T\left(\cfrac{n}{4}\right)+\cfrac{cn}{2}\right)+cn \\
& = 4T\left(\cfrac{n}{4}\right)+2cn
\end{aligned}
$$
이제 여기서 $n=2^k$ 라 해봅시다. 그러면 $k=\log_2 n$ 으로 나타낼 수 있습니다.
그리고 위의 식에 n과 k를 대입합니다. 그러면 $T(n)=2^k\left(T\left(\cfrac{n}{2^k}\right)\right)+kcn$ 이 나오게 됩니다.
따라서 다시 $n$에 대해서 나타낸다면($k=\log_2 n$ 대입),
\[
T(n) = \cancelto{n}{2^k} \left( T \left( \cfrac{n}{\cancelto{n}{2^k}} \right) \right) + cn\log_2 n
\]
입니다. 곧 $T(n)=nT(1)+n\log n=O(n\log n)$ 으로 나타낼 수 있습니다.
힙 정렬(Heap Sort)
힙 정렬은 말 그대로 힙(Heap) 자료 구조를 이용해서 정렬을 수행하는 알고리즘입니다. 힙에 넣고 빼면서 정렬을 수행합니다. 따라서 힙을 구성하고 빼내는 시간 복잡도가 곧 힙 정렬의 시간 복잡도입니다.
힙 정렬의 과정은 아래와 같습니다.
- 힙 구성: $n$개 원소에 대해서 힙을 구성합니다. 이때 시간은 $O(n)$입니다.
- 힙 정렬: 힙에서 루트 원소를 꺼내서 배열의 마지막 원소와 교환한 후에, $n-1$ 개 원소에 대해서 다시 최대 힙을 만듭니다. 이 과정이 $n$번 이루어지고, 각각 최대 힙을 만드는 작업이 $O(\log n)$ 번 이루어집니다.
증명:
$k$ 레벨 깊이의 트리에 대해서 원소가 $n$개이면, $2k^{-1}\leq n \leq 2^k$ 입니다. 그리고 $i$ 번째 원소의 깊이는 $2^{i-1}$ 입니다. 첫 번째 for 루프에서, 힙 정렬 함수는 각각 자식 노드를 가진 모든 노드에 대해서 재귀적으로 adjust 함수를 호출합니다. 이때 adjust 함수는 힙을 구성하거나 복원할 때 사용되는 함수입니다. adjust 함수의 시간 복잡도는 $O(\log n)$ 입니다.
따라서 이 루프에서 소비되는 시간은 각 레벨에서의 노드 수와, 각 노드가 이동할 수 있는 최대 거리를 곱한 값이 됩니다.
$$
\sum\limits_{1\leq i \leq k}{2^{i-1}(k-1)} = \sum\limits_{1\leq i \leq k-1}{2^{k-i-1}i} \leq n = \sum\limits_{1\leq i \leq k-1}{\cfrac{1}{2^i}} < 2n = O(n)
$$
따라서 힙을 구성하는데 $O(n)$, 그리고 힙을 꺼내어 정렬하는데 $O(\log n)$이 소요된다면, 총 시간 복잡도는 $O(n\log n)$이 됩니다.
📚 참고 자료
- Horowitz, Ellis, Sahni Sartaj, and Mehta Dinesh. Fundamentals in data structures in C++. 2nd ed. Silicon Press, 2007.
- 윤성우. 윤성우의 열혈 자료구조. n.p.: 오렌지미디어. 2012.
잘못된 정보가 있다면 지적해주시면 감사하겠습니다.