


Google I/O Extended Seoul
지난 7월 29일 토요일 코엑스에서 열린 구글 I/O Extended Seoul에 다녀왔는데요, 어떤 발표들과 이벤트들이 있었는지 후기를 남깁니다.
이벤트들
Google I/O Extended Seoul에서는 다양한 이벤트 체험 부스 역시 준비되어 있습니다. 사실 쉬는 시간이 20분 밖에 되지 않는 것에 비해 참여자 수는 1000여 명 가까이 돼서, 이벤트 존을 모두 체험하는 것은 현실적으로 어려웠는데, 그 중에서 Photobooth에서 사진 하나 건지는 것으로 만족했습니다.

참고로 지도는 이렇게 되어 있습니다.
401호가 가장 으리으리하게 큽니다. 402호는 평범한 크기이고, 403호는 가보지 않아서 모르겠습니다.

참여하게 되면 이렇게 입장용 밴드를 붙여줍니다.
기념품도 수령할 수 있었는데, Google I/O 가 적힌 티셔츠 하나와 스티커 등을 받았습니다.

Google I/O 2023 Extended Seoul은 이렇게 다양한 GDG와 GDSC 단체가 협력해서 진행되고 있습니다. 사실상 봉사 활동인데, 고생 많으신 것 같습니다.
발표 Agenda

발표 아젠다는 위처럼 있습니다.
듣고 싶었던 것은 많았는데 시간대별로 하나를 선택해야 해서 아쉬웠습니다.
Track 1같은 경우는 주로 안드로이드, Flutter 등의 모바일 개발이나 Go 언어 등의 개발에 관련된 이야기가 분포되어 있습니다.
Track 2같은 경우는 주로 Google Cloud 관련된 이야기가 분포해 있었고
Track 3같은 경우는 인공지능을 비롯하여, 요새 핫한 LLM 모델에 관한 이야기가 많이 있었습니다.

제가 선택한 아젠다는 이렇게입니다.
일단 인공지능 쪽은 이제는 별로 관심이 없어서 Track 3 쪽은 갈 일이 없었고, Track 2에 많이 분포해 있네요.
Flutter를 위주로 들었고, 나머지는 GCP 쪽으로 선택을 했습니다.
맨 마지막에 ‘Apache Airflow in Google Cloud’를 선택할까 아니면 Go 언어를 선택할까 고민을 많이 했습니다. Go 언어에도 요새 관심을 많이 갖고 있어서, 원래는 Go 언어를 들으려고 했습니다. 하지만 DevOps에도 관심을 갖고 있어서 마지막에 마음을 바꾸어서 ‘Apache Airflow in Google Cloud’를 선택했습니다. 사실 하나도 이해 못해서 그냥 Go 언어 선택할 걸 그랬습니다🥲.
3:20-4:00까지는 ‘Flutter Google I/O 2023 Recap’과 ‘일 잘하는 개발자는 회사에서 어떻게 일할까?’를 선택했어야 했는데, 둘 다 듣고 싶어서 저는 Flutter Google I/O 2023 Recap에 가있었고, 다른 분에게 일잘알 발표 녹음을 부탁하는 식으로 둘 다 들었습니다.
이중 가장 유익했던 것은 뭐니뭐니해도 Flutter Google I/O 2023 Recap이었습니다. Flutter 3.10 버전에서 무엇이 변화하였는지를 빠르게 찾아볼 수 있었고, 잘 알지 못했던 부분들 역시 정확하게 되짚어 볼 수 있었습니다.
반면에 Apache Airflow in Google Cloud같은 경우는, 아무래도 Airflow 자체를 써본 적도, 들어본 적도 없었기 때문에 이러한 세상이 있구나 정도로만 알게 됐습니다. 나중에 접해볼 일이 있겠죠.
세상의 모든 데이터베이스 이야기, 윤명식
데이터베이스의 종류와 특징, 역사에 대해서 알 수 있는 발표였습니다. 교양 느낌의 가벼운 발표였으나, 나름 그 안에 담겨진 내공이나 지식들은 결코 가벼운 것들이 아니었습니다.
보통 프로젝트를 할 때 DB를 무엇을 선택할 것인지에 대해서 많은 고민을 하게 됩니다. 아무 생각 없이 SQL을 선택하게 되는 경우가 많은데, 프로젝트의 특성, 데이터 모델의 특성에 따라서 상황에 유리한 DB는 크게 달라집니다. 아무 생각 없이 RDBMS만 고를 수 없는 이유입니다.
굉장히 많은 DB가 소개되었습니다. 기껏해야 지금껏 Oracle, MSSQL, MySQL, PostgreSQL같은 유명한 RDBMS나, MongoDB, Firestore, Redis같은 자주 사용되는 NoSQL DBMS 정도만 알고 있었습니다. Neo4j 같은 특수한 형태의 DB는 이름만 알고 있었구요. 이번 발표를 통해서 이름도 새로운, 그러나 유용한 DB를 알게 되었고, 또한 NoSQL, NewSQL DB 중에서 어떤 환경에 유리한 DB들이 있는지도 듣게 되었습니다.
우선 데이터베이스는 크게 세 종류로 나눌 수 있습니다. 발표 역시 이 단원들로 분류되어 진행됐습니다.
- RDBMS(SQL)
- NoRDBMS(NoSQL)
- NewSQL
RDBMS
RDBMS는 흔히 관계형 데이터베이스라 불리우는, 테이블의 형태로 데이터를 저장하는 데이터베이스를 말합니다. 유구한 역사를 지녔고, ACID(Atomicity, Consistency, Isolation, Durability)라는 특성을 지녔습니다. ACID 기반의 특성은 RDBMS가 현재 IT 세계에서 가장 범용적으로 사용되는 데이터베이스로 확립되게 만드는 기반을 제공합니다.
Oracle DBMS는 세계에서 가장 널리 쓰이는 기업용 RDBMS이며, MySQL, PostgreSQL은 오픈소스 RDBMS에서 가장 유명한 두 쌍두마차입니다.
구글 역시 Google Cloud SQL 서비스를 통해서 자체적인 RDBMS 서비스를 제공합니다. MVCC(다중 버전 동시성 제어, Multi-Version Concurrency Control) 모델에 대한 이야기도 나왔습니다. 현대적인 RDBMS의 핵심인데, MVCC를 지원하는 RDBMS의 경우 동시성 처리를 지원하기 때문에 이를 지원하지 않는 RDBMS보다 훨씬 빠른 입출력 속도를 보장합니다. 또한 ACID를 지원하기 위해서 MVCC를 구현합니다.
PostgreSQL에 대한 팁도 나왔습니다. PostgreSQL같은 경우 MySQL 대비 성능적인 이점 등으로 최근 점유율이 급부상하는 오픈소스 DB입니다. 그런데 이번 발표를 통해서 PostgreSQL이 마냥 만능은 아니구나라는 것도 알게 됐습니다. RDBMS는 트랜잭션이 발생할 때마다 원자성을 보존하기 위해서 트랜잭션 ID를 보존합니다. 기본적으로 Oracle DB, MySQL 등과 같은 MVCC 모델에서는 Undo Tablespace를 생성해서 저장을 합니다.
반면 PostgreSQL은 Undo Tablespace를 생성하지 않고, 새 버전에 대한 정보를 테이블과 함께 저장을 한다고 합니다. 그렇기 때문에 PostgreSQL은 업데이트를 많이 하게 되면 테이블이 어마무시하게 커지는 문제가 발생을 합니다. 그래서 vacuum이라는 것을 한 번 돌리면서 필요없는 롤백 정보들을 전부 날린다고 합니다.
이러한 점을 알고서 PostgreSQL을 쓸 지, MySQL을 쓸 지 정해야 할 것 같습니다.
그 외에도 기억에 남는 DB로는 Cockroach DB(바퀴벌래 디비)라는 것이 있습니다.
이 DB는 배포가 매우 쉽다고 합니다. cockroach.exe 파일 하나만 있으면 매우 쉽게 배포를 할 수 있도록 도와준다고 합니다. 그리고 절대 죽지 않는 DB라고 합니다. 자가 복제 기능(다중 활성 능력)을 탑재해서, 매우 높은 고가용성을 유지합니다.
NoRDBMS
RDBMS가 ‘범용성’을 기반으로 탄생한 데이터베이스라면, NoRDBMS, 즉 NoSQL은 ‘목적성’을 기반으로 탄생한 데이터베이스입니다. NoSQL은 SQL보다는 분명 범용성이 떨어지지만, 어느 특정한 상황에서는 SQL이 따라올 수 없는 성능적인 이점을 갖거나, 편의성을 챙길 수 있습니다.
NoSQL의 대표적인 DB로는 아래와 같은 상품들이 있습니다.
- Firestore
- Mongo DB
- Mongo DB같은 경우는 NoSQL 계에서 많이 사용되는 DBMS입니다
- SQL의 단점은, 스키마의 변경이 존재할 시, DB 서버를 내리고 데이터를 조작해야 합니다. 흔히 말하는 서버 점검이 필요합니다.
- 이러한 Schema-less DB의 장점은, JSON 형태로 데이터를 집어넣을 수 있으니 데이터의 변형에 있어서 상대적으로 자유롭습니다.
- 카산드라
- Insert에 특화된 DB라고 합니다. 시계열 데이터를 다룰 때 카산드라를 이용하면 좋다고 합니다
JOIN은 지원하지 않는 Big Table DB라고 합니다.
- Redis
- 캐시로 많이 사용되는 Key-value DB 입니다.
어떤 데이터베이스를 사용해야 할까?
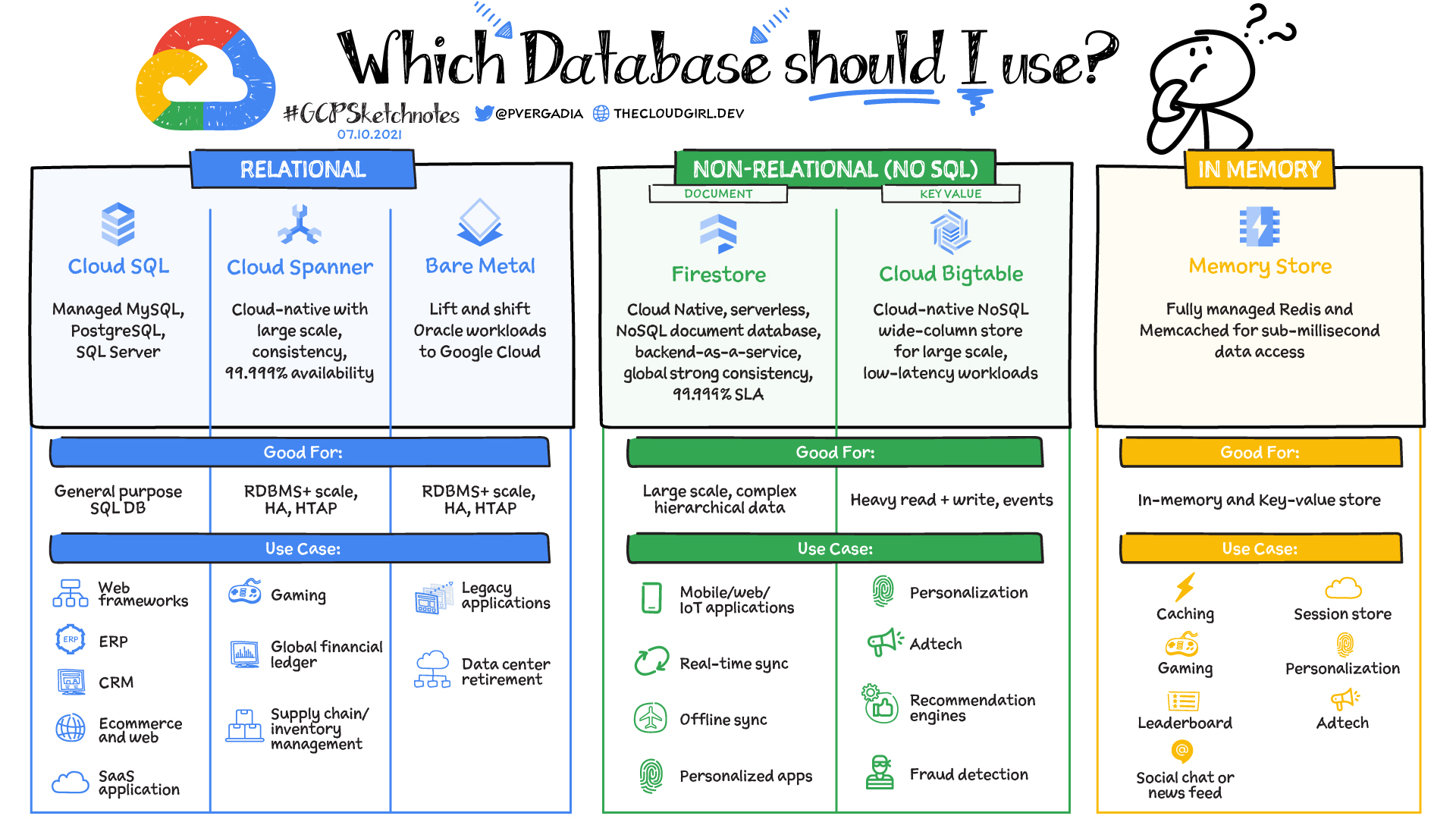
어떤 상황에서 어떠한 데이터베이스를 사용하는 게 좋을까요? 정답은 없지만, 이러한 장표를 발표에서 소개해주셨습니다.
관계형 데이터베이스의 경우는, 우리가 흔히 생각하는 많은 경우에서 범용적으로 사용될 수 있습니다. Web fremeworks, SaaS 서비스, Gaming, Financial Ledger와 같은 서비스는 대표적인 RDBMS를 사용하는 서비스들입니다.
NoSQL은 목적성을 갖는 DB입니다. 그렇기 때문에 원하는 상황에 적합하게 맞추어서 사용을 하면 된다고 하는데, 장표에서는 일반화시켜서 상황을 제시하고 있습니다.
신기하게도 Firestore은 Firebase를 백엔드로 할 때 많이 사용하게 됩니다. 특히 모바일 개발 시에 백엔드 개발 시간을 단축시키는 차원에서 Firebase는 유용한 선택지가 되기도 하고, 이중 Firestore은 NoSQL DB로써 좋은 선택지가 됩니다.
Redis같은 인메모리 DB의 경우는 당연히 세션 저장, 캐싱 등에서 많이 사용이 되고, 또한 속도가 매우 중요한 환경(특히 게임)에서 사용된다고 합니다.
NewSQL
NewSQL은 2010년 대에 이르러서 새롭게 정립된 개념으로써, RDBMS의 ACID를 보장하면서 동시에 NoSQL의 수평적 확장이 가능한, 장점들을 각각 합친 DBMS입니다.
RDBMS는 ACID를 보장하지만 수평적 확장이 쉽지 않습니다. NoSQL은 수평적 확장이 쉽지만 ACID가 보장되지 않습니다. 이를 적절히 합친 데이터베이스입니다.
사실 이렇게 들어도 잘 개념이 와닿지는 않았습니다. 발표에서는 기억에 남는 DB는 크게 세 가지입니다.
구글에서는 빅쿼리라고 하는, 거대한 데이터를 처리할 수 있는 클라우드 서비스를 제공합니다. 한 번 찾아봐야겠네요.
- 그래프 데이터베이스
관계 지향적인 데이터 모델을 설계할 때, 사용되는 데이터베이스입니다.
이때 주의할 것은 이미 잘 알려진 사실이지만, 관계형데이터베이스(Relational Database System)에서 관계형(Relational)이란 말은 행렬에서 따온 수학적인 용어로, 실제 엔티티와 엔티티 사이의 관계(Relation)와는 관련이 없는 용어입니다.
그래프 데이터베이스는 각 Vertex(Node)들 사이의 관계를 표현하는데 적합한 데이터베이스이며, 이는 추천 시스템 등에서 상호 연관된 요소를 저장하기에 유리하다고 합니다.
기존 관계형 데이터베이스(SQL)은 대용량의 테이블을 JOIN하는데 있어서 성능 저하를 피하기 어렵습니다. 그러나 그래프 데이터베이스는 연결을 기반으로 하는 데이터베이스이고, 이러한 대용량 데이터를 처리하는데 자유롭습니다.
AWS Neptune 등의 상품이 있습니다.
- Vector Database

벡터는 서로다른 성질이나 특성을 가진 객체들을 설명하는 데이터들간의 수학적인 관계로써, 벡터 데이터베이스는 대량의 고차원 데이터를 저장하고 쿼링하는 데 있어 벡터의 형태로 최적화한 데이터베이스입니다.
도큐먼트들을 임베딩하여 벡터 형태로 바꾼다고 합니다. 이렇게 바꾸는 주된 목적 중 하나는 유사도를 찾기 위함인데, 이것이 생성형 인공지능(Generative AI)가 등장하면서 크게 주목을 받고 있다고 합니다.
다양한 데이터베이스에 대해서 알 수 있었던 발표였습니다.
키워드: Vector Database, RDBMS, Graph Database, New SQL, NoSQL
Google Cloud를 최대한 활용하여 Data Engineering하기, 김정우
자동차 부품들에 문제가 생기면 WD-40을 뿌리면 됩니다. 데이터에는 WD-40을 뿌릴 수 없으므로, GCP를 사용합니다.
발표자 분의 비유입니다.
발표자 분이 상당히 재밌었습니다. 위트가 있었고, 중간중간 재밌는 농담도 있었습니다.
위트있었고 전달력이 있었던 것과는 별개로, GCP에 대한 내용은 제가 이해하기는 힘들었습니다. 그냥 이런 게 있구나 키워드를 위주로 기억해두고, 나중에 사용할 일이 있으면 찾아서 사용해야겠습니다.
GCP에는 다양한 데이터 엔지니어링을 위한 솔루션을 제공하는데, Big Query, Data fusion, Cloud hadoop 등의 data prop 등의 솔루션을 제공합니다. 발표에서 주로 설명한 것은 Dataflow와 Big Query입니다.
Dataflow ETL pipeline에 대해서 설명을 했습니다. Dataflow는 GCP에서 제공되는 완전 관리형 서비스로, 데이터 추출, 변환, 적재 (ETL) 및 데이터 분석 작업을 위한 데이터 처리 파이프라인을 설계하고 실행할 수 있게 해줍니다. 서버리스와 병렬 데이터 처리 서비스로서 대용량 데이터를 효율적으로 처리하기 위해 자동으로 확장됩니다.
데이터를 수집하고(Cloud Storage, Big Query 등으로부터), 이를 변환하고, 데이터를 분산 리소스 상에서 처리하며, 처리된 데이터를 다시 Big Query나 Cloud Storage, 혹은 기타 DB 등 적절한 데이터 싱크로 적재하며, 마지막으로 이 프로세스의 결과를 분석용 하위 서비스나 저장된 위치에 출력하기까지 모든 기능을 별도의 백엔드 구현 없이 오직 구글 클라우드의 서비스만을 활용해서 끝마칠 수 있습니다. (돈만 낸다면요 😅)
Dataflow ETL Pipeline을 사용하게 된다면, 서버리스, 확장성, 내결함성, 통합성 등의 장점을 얻어갈 수 있다고 구글은 설명합니다. (돈만 낸다면요 😅)
돈 얘기에서 알 수 있듯이, 클라우드는 비용이 가장 큰 문제입니다. 빈 쿠버네티스만 올려도 한 달에 10만 원씩 녹는게 GCP입니다. 발표에서도 비용 문제를 언급했습니다. 그렇기 때문에 클라우드 서비스를 이용할 때는 그 비용이 BE를 직접 구현하는 비용과 비교해봐서, 어느 것이 더 경제적일지를 현실적으로 따져봐야 하는 것 같습니다. 클라우드 기술의 혜택을 누리되 Over Engineering은 피해야 할 것 같습니다.
발표에서는 직접 Azure Block Storage 속 JSON 데이터들을 GCP Dataflow에 집어넣는 것을 시연했습니다. 또한, Big query에서 MongoDB, Elastic Search 등 다른 DB로 내보내는 템플릿을 제공한다고도 합니다. 이러한 서비스를 이용하게 될 때 가장 먼저 체크해야 할 사항은 개발자가 한 회사의 서비스에 종속적으로 묶이는 것은 아닌지 검토해야 하는데, 이처럼 외부 서비스와도 잘 연동되는 것이 Dataflow의 장점이라고 설명합니다.
BigQuery OMNI에 대해서도 설명했습니다. 같은 리전 안에 있는 DB 데이터를 공유/관리하는 서비스입니다.
BigQuery Data set의 리전이 같으면, AWS S3, Azure Block Storage 들간의 데이터를 가져올 수 있습니다. 이때 데이터를 복제하는 것이 아니라 External Connection 방식으로 링크된 정보를 갖고 오는 방식으로, 실제로 데이터가 물리적으로 복제되어 GCP 안의 공간을 차지하는 것은 아닙니다.
데이터 엔지니어링 단계에서 어떻게 구글 클라우드 서비스를 이용하는 지, 실무자들의 대화를 엿볼 수 있는 발표였습니다. 만약에 데이터를 실제로 만지게 된다면, 그때에 가서 이날 들은 키워드들을 바탕으로 배워갈 수 있을 것 같습니다.
키워드: BigQuery OMNI, Dataflow ETL Pipeline, Cloud Hadoop
Dagger Hilt로 의존성 주입하기, 안성용

이 발표부터는 401호로 넘어왔습니다. 401호 가보니깐 넓고 시원한 곳에서 진행됐습니다. 사람도 엄청 많아서, 자리 차지하는데 애좀 먹었습니다.

코틀린과 안드로이드 개발에 관한 이야기입니다. 하나도 알아듣지 못 했습니다.
Flutter에 Clean Architecture를 얹어보자 - 개정판, 양수장
Flutter Festival GDG Songdo의 1년 전 발표의 개정판입니다. 개인적으로 가장 기대하던 연사였습니다. 미리 유튜브에서 듣고 갔는데, 역시나 아키텍처의 관점에서 배울 점들이 많았습니다.

이 주제는 꽤 유익해서 추후에 별도의 포스팅으로 다룰 수 있으면 다루겠습니다. 어떻게 클린 아키텍처로 플러터 어플리케이션을 설계하는지에 대해서 소개합니다.
이 글에서는 간단히만 발표의 내용을 소개하겠습니다.
Overview of Clean Architecture
유연하고 효율적인 앱을 만드는 방법
클린 아키텍처는 로버트 C. 마틴이 제시한 소프트웨어 설계 개념으로, 어떻게 유연하고 효율적인 어플리케이션을 만들지에 대한 방법론입니다.
소프트웨어 아키텍쳐는 선을 긋는 기술이며, 반대편 경계를 알지 못하게 하는 설계라고 마틴은 설명합니다. 이는 현대 소프트웨어 개발론의 꽃인 객체지향의 핵심 원리와도 상응합니다.
클린 아키텍처의 장점은 다음으로 정리할 수 있습니다.
- 분리된 책임과 유지 보수성: 클린 아키텍쳐는 각 계층별로 책임을 분리하여 코드를 단순하고 명확하게 유지합니다. 이로 인해 유지 보수가 쉬워지고, 한 계층의 변경이 다른 계층에 영향을 미치지 않습니다.
- 테스트 용이성과 안전성: 각 계층은 독립적으로 테스트할 수 있기 때문에 단위 테스트 및 통합 테스트 작성이 용이합니다.
- 유연성과 확장성: 클린 아키텍처는 외부 의존성을 내부로부터 격리시키기 때문에, 새로운 요구사항을 수용하거나 기존 기능을 변경하는 데 더욱 유연하고 확장 가능합니다. 외부 시스템과의 결합도를 최소화하여 기술적 교체가 원활하게 이루어집니다.
- 도메인 주도 개발: 도메인 주도 개발은 비즈니스 로직에 초점을 맞추는 개발 방법론으로, 클린 아키텍처와 잘 결합되어 복잡한 도메인 모델을 잘 이해하고 표현할 수 있게 합니다.
- 팀 간 협업 용이성: 각 계층은 분리되어 있으므로 다양한 팀이 독립적으로 작업할 수 있고, 서로의 작업에 영향을 덜 받습니다. 이는 팀 간의 협업을 원활하게 만들어 줍니다.
Layers in Clean Architecture
로버트 마틴은 구체적으로 4단계의 레이어를 제시합니다. 다만 실무에서 사용되는 실질적인 레이어는 3단계라고 합니다.
프레임워크와 드라이버 계층은 외부 시스템과 상호작용을 하는 인터페이스 계층입니다. 이 레이어를 설계할 때 중요한 점은 외부 시스템 간의 결합도를 최소화하고, 유지 보수하기 적절한 형태로 변형하는 것입니다. 패시브한 형태의 뷰를 만들어야 합니다. 흔히 선언형 UI를 설명할 때 자주 소개되는 개념인 패시브 뷰는, 다른 말로 해서 Stupid View, 멍청한 뷰라고 불리기도 합니다. 멍청한 뷰는 명령형 뷰와 다르게, 그 자체적으로 복잡한 로직과 의존 관계를 내포하지 않고 단순한 설계를 지향할 수 있기에, 현대 웹 클라이언트 프레임워크에서 필수적으로 채용되는 설계 개념입니다. 플러터 역시 선언형 UI를 충실하게 따르고 있습니다.
엄밀히 따진다면 프레임워크 계층과 드라이버 계층은 분리되어야 합니다. 프레임워크 계층은 UI를 담고 있으며, 드라이버 계층은 데이터 소스, 리포지토리 구현체, 플랫폼 특화 코드를 담고 있습니다.
인터페이스와 어댑터 계층은 도메인 계층의 상위 비즈니스 로직과 프레임워크 및 드라이버 계층의 외부 관심사 사이의 가교 역할을 하는 계층입니다. 도메인과 UI를 연결하고, 비즈니스 로직을 UI로부터 분리하고, 종속성 반전(Dependency Inversion)의 원리를 적용하여 도메인 레이어가 특정 구현과 독립적인 상태를 유지하도록 촉진합니다.
도메인 계층은 비즈니스 로직을 캡슐화하여, 서로 다른 엔티티 간의 상호 작용을 정의하는 계층입니다. 도메인 로직을 실행하는 계층으로 사용자의 요구 사항에 맞추어 Use Case를 구현합니다. 구현 계층과 완전히 분리되어 유연성을 가집니다. 도메인 계층은 캡슐화와 독립성을 유지해야 합니다. 또한 비즈니스 로직을 추상화해야 합니다. 이때 Use Case라는 도메인 계층의 핵심 개념이 등장하니다.
엔티티 계층은 핵심 비즈니스 개체 및 개념을 나타내는, 단순한 데이터 클래스가 포함된 계층입니다. 실무에서는 도메인과 엔티티를 묶어서 사용한다고 합니다.
MVC 모델로 표현하자면, 정확히 매칭되지는 않으나 Model은 도메인과 엔티티 계층, Controller는 인터페이스와 어댑터 계층, V는 프레임워크와 드라이버 계층으로 표현할 수 있을 것 같습니다.

발표에서 소개된 아키텍처 다이어그램의 형태입니다. Presentation Layer에서는 사용자와 상호작용하는 최상단의 로직을 구현합니다. 이때 Widget과 상태 관리 패키지(bloc, Provider)가 보입니다. Flutter에서 위젯은 선언형 UI를 따르고 있어 패시브 뷰로 구현되어 있습니다. 그렇기 때문에 위젯 자체에는 그 어떠한 상태도 담고 있지 않은 Stateless 위젯으로 구현되어 있는데요, 그렇기 때문에 Flutter는 이 상태를 위젯에 매번 전달을 해주어야 합니다. 이 과정이 다소 번거롭고 나중에 문제 발생 여지가 많아져서, 별도의 상태 관리 패키지를 통해서 상태를 전역에서 관리하자는 개념이 상태 관리입니다.
한편 Domain Layer는 Use Case를 바탕으로 비즈니스 로직을 구현합니다. Data Layer는 데이터 원본을 담고 있습니다. 이 둘을 연결하는 것이 Data Repository입니다.
Presentation Layer와 선언형 UI
선언형 UI를 알기 위해선 먼저 명령형 UI에 대해서 알아야 합니다.

위와 같은 형태의 위젯이 있다고 가정합니다. 이때 ViewA 안에 있는 위젯 ViewB에서, c1과 c2가 c3로 변경되는 위젯의 변화가 일어났다고 가정합니다. 이를 명령형으로 구현하면 마치 아래와 같이 구현할 수 있습니다.
// 명령형
b.setColour(red); // b의 색을 빨간색으로 변경
b.clearChildren(); // b의 하위 자식을 지운다
std::unique_ptr<ViewC> c3 = std::make_unique<ViewC>(...); // c3 객체 생성
b.add(std::move(c3)); // c3 객체 전달몇몇 C++로 구현된 오래된 프레임워크에서는 위와 같은 방식의 명령형 UI가 사용된다고 들었습니다 (이제는 그렇지는 않은 것 같습니다). 명령형 UI는 그 자체적으로 상태를 저장합니다. 그렇기 때문에 자신이 노란색이라는 상태, c1, c2라는 자식을 들고 있다는 상태를 저장하고 있습니다. 때문에 이를 변경하기 위해서는 명령형으로 하나하나 바꾸어주어야 합니다.
그에 반해서 선언형 UI는 아래와 같습니다.
// 선언형
return ViewB(
color: red,
child: const ViewC(),
);선언형 UI의 경우 상태를 따로 저장하지 않습니다. 그저 패시브한 뷰에 어떻게 화면을 그릴 것인지를 매번 전달할 뿐입니다. Flutter 역시 이 선언형 UI를 정말 충실하게 따르고 있습니다.
선언형 UI를 한 문장으로 표현하면 아래와 같이 표현할 수 있습니다.
UI = f(state)
UI는 스크린의 레이아웃입니다.
state는 어플리케이션의 상태입니다.
f는 우리가 정의한 빌드 메소드입니다.
선언형 UI는 모든 것이 위 형태로 이루어집니다.
선언형의 한 가지 단점은, 따로 상태를 저장하지 않기 때문에 매번 상태를 지속적으로 관리해주어야 합니다. 위젯 트리를 기반으로 하는 플러터에서 이 상태를 전달하는 과정이 번거롭고, 자칫 위젯들간의 종속성을 갖게 하는 위험도 있기에, 선언형 프레임워크에서는 이 상태를 전역에서 관리하는 상태 관리를 동반합니다.



Flutter의 상태 관리 패키지는 bloc, Provider, GetX가 대표적으로 존재합니다. 제가 주력으로 쓰려고 하는 상태 관리 패키지는 riverpod입니다. 발표 자료에 riverpod이 등장하지 않아서 아쉬웠지만, 대신 발표자 분께서 Provider의 확장판인 riverpod 역시 뜨고 있다고 언급해주어서 기분은 좋았습니다.
발표에서는 실제 코드도 예시로 보여주면서 어떻게 클린 아키텍처를 적용하는 지를 보여주었습니다. 이 날 발표에서는 bloc을 사용하여 상태 관리하는 모습을 보여주었습니다.
Domain Layer와 Data Layer

발표에서 소개된, 도메인 계층과 데이터 계층이 어떻게 상호작용하는 지에 대한 장표입니다. 이 역시 실제 코드로 예시를 들어주어서 좋았습니다.
Folder Structure

이 장표는 위에서 소개한 레이어들을 담는 폴더 구조에 대한 장표입니다.
사실 발표는 더 많은 내용들과, 상세한 코드들을 예시로 담고 있어 좋았습니다. 코드를 수반한 발표는 자칫 그 속도가 너무 빠를 경우, 혹은 코드가 너무 방대할 경우에 이해하지 못하고 넘어가게 하는 불친절한 발표를 수반할 수 있기도 합니다. 특히 별도의 영상 녹화가 진행되지 않는 이러한 발표는 모든 내용을 사진으로 남기지 않는 이상, 정리하기 쉽지 않은 것도 사실입니다.
사실 이 발표 역시 제한된 시간 안에 많은 내용을 수반하느라, 속도감 있게 전개된 것도 사실입니다. 그렇기에 놓친 내용들도 많이 존재합니다. 그럼에도 불구하고 발표자가 코드에서 어떠한 부분이 중요한 지를 하이라이트하면서 짚어주셨고, 최대한 개념과 실제 예시를 1대 1로 매치하여 설명하면서 흐름을 놓치지 않도록 주지시켜주어서 좋았습니다. 굉장히 도움이 되는 발표였습니다.
키워드: 클린 아키텍처, 상태 관리
Flutter Google I/O 2023 Recap
기술적으로 따지면, 가장 도움이 되는 발표였습니다. Flutter Youtube에 가보시면 Flutter at Google I/O 2023 재생 목록이 있는데, 여기서 2023 Google I/O에서 Flutter 관련 변화점들을 한 눈에 알아볼 수 있습니다.

그러나 분량이 꽤 만만치 않으므로, 이를 다 챙겨보기란 쉽지 않습니다. 이번 발표를 통해서 Flutter의 변화점들을 40분만에 챙겨볼 수 있었습니다.
참고로 여담이지만 작년까지 Google I/O에서는 Flutter 세션이 따로 존재했는데, 올해부터는 사라졌다고 합니다. 얼른 손절하고 네이티브로 넘어가라는 구글의 암시일까요? 🤔🤔
이번 발표가 특히 좋았던 점은, 발표 자료를 연사 분께서 공유해주셨습니다. 아래 링크에서 확인해보실 수 있습니다.
Flutter Google I/O 2023 Recap 박제창 @I/O Extended 2023 Seoul
Flutter에 대해
발표자 분께서 한 가지 재밌는 이야기를 해주셨습니다. 2020년까지만 하더라도, 이런 자리에서 사람들에게 ‘Flutter에 대해 알고 있습니까’라고 질문을 했다고 합니다. 그런데 2020년 이후부터는, 그대신 ‘Flutter를 사용해보셨습니까’라고 질문을 한다고 합니다. 그만큼 Flutter의 위상이 크게 올라갔다는 것을 보여주는 지표인데요, 실제로도 발표자 분께서 Flutter를 사용해봤냐는 질문에 402호에 있는 꽤 많은 사람들이 손을 들어서 저 역시도 놀랐습니다.

Flutter의 엔지니어링 로드맵이라고 합니다. Flutter는 완전한 오픈소스이기에, 이 기능들은 Github에서 직접 확인해볼 수 있습니다. Github 이슈란에서 어떠한 기능들이 주로 토의되고 있는지, 어떠한 기능들이 머지되고 있는지를 직접 확인할 수 있습니다.
눈에 띄는 것은 drag and drop인데요, 여기 장표에 나와있다는 것은 반대로 말하면 2023년 7월 현재에도 이 기능을 지원하지 않나 봅니다. 얼른 발전했으면 좋겠네요.

참고로 Google I/O 행사에서 매번 이 게임을 이벤트 부스에 설치한다고 하는데요, 이 게임 역시 Flutter로 만들어졌다고 합니다. Flutter로 게임을 만들 수 있다는 사실 알고 계셨나요? 저는 코딩애플 님 영상을 보고서 그냥 재밌구나 정도로 생각했는데, 이렇게 직접 보니깐 신기하긴 하네요.
근데 정작 저 게임을 저는 이번 이벤트 부스에서 못 찾았거든요? 대체 어디 있었는지 모르겠습니다.
Dart 상에서의 변화
Dart 역시 Dart 3로 메이저 버전 업을 맞았습니다. Dart 3부터 완벽한 100% Null Safety, 패턴 매칭, 새로운 클래스 Modifier들이 등장했습니다.
가장 큰 변화는 Destructuring과 Record, Class modifier입니다.
Destructuring은 다음과 같이 클래스 내의 변수들을 한 번에 따로따로 저장할 수 있는 언어적 기능입니다.
final (name, section, track) = speakerInfo(io23SeoulSpeaker);이와 비슷한 기능들은 현대적인 프로그래밍 언어라면 이미 많이 보셨을 겁니다.
예를 들어 C++에서는 아래와 같은 형태로 Destructuring을 자주 사용하게 됩니다.
for (const auto [uid, age] : User) {
// ...
}근데 사실 생각해보면, 사실 굉장히 오래된 언어인 C++조차도 Destructuring을 지원한 지 10년은 된 것 같은데, 정작 모던 프로그래밍 언어인 Dart에서 패턴 매칭을 지금에서야 지원을 한다는 게 놀랍기도 합니다. JS 등 다른 더 현대적인 언어들은 말할 것도 없이 비슷한 기능들을 훨씬 오래 전부터 사용하고 있었는데, 조금 아쉽기도, 한편으로는 이제라도 돼서 다행이기도 합니다.
Record는 Python의 튜플과 비슷합니다. switch 문법에도 소소한 추가사항이 있었고, 또한 여러가지 객체지향 프로그래밍을 강화할 수 있는 클래스 수정자들이 추가되었습니다. 이로써 Dart는 한층 더 현대적인 객체지향 프로그래밍을 가능케해주는, 그리고 프로그래머로 하여금 클래스 설계의 선택권을 넓히는 강력한 언어로 재탄생한 기분이 듭니다.
자세한 기능의 설명은 Flutter 3.10 Dart 3.0 업데이트 신규 문법 총정리(코드팩토리) 영상을 참고하면 도움이 될 것입니다.
한편 DevTool 역시 변화가 있었다고 합니다.
Material 3의 적용
Material 3의 디자인이 디폴트로 적용되었습니다. 커스텀 디자인을 쓰는 경우라면 크게 신경을 쓰지 않겠지만, Material 3의 디자인을 사용하는 경우 구글에서 디자인한 유려한 Material의 혜택을 누릴 수 있게 되었습니다.
동시에 여러 가지 좋은 라이브러리들을 소개해주셨습니다.
- dynamic_color
- https://pub.dev/packages/dynamic_color
- 색 관련 라이브러리같습니다
- google_fonts
- https://pub.dev/packages/google_fonts
- Typography 관련 패키지인데, 이건 진짜 꿀팁인데 폰트 렌더링 성능을 향상시킬 수 있는 라이브러리라고 합니다
- 일반적으로 폰트를 Assets에 저장해놓고 쓰게 되면, 페이지 로딩 시 폰트를 다운로드하느라 시간이 많이 걸리는데, 이 구글 폰트 라이브러리를 쓰게 되면 이 폰트 로딩 속도를 비약적으로 향상시킬 수 있다고 합니다. 자세한 원리는 기억이 나지 않지만, 꿀팁인 것 같습니다
- flutter_adaptive_scaffold
- https://pub.dev/packages/flutter_adaptive_scaffold
- 반응형 레이아웃을 위한 adaptive scaffold 패키지입니다
Firebase
Firebase와 Flutter 간 사이가 더 돈독해졌다고 합니다. 여러가지 Firebase for Flutter 기능들이 추가되었고, 문서 역시 더 강화되었다고 합니다. 추가적으로 FlutterFire CLI가 더 업그레이드되었고, 여러 플랫폼(크롬, 안드로이드, 데스크톱)을 공식적으로 추가 지원한다고 합니다.
Flutter Engine
사실 이 부분이 Flutter 3.10에서 가장 큰 변화점같습니다. Flutter는 전통적으로 2D 그래픽 엔진인 SKIA를 그 기반 렌더링 엔진으로 두고 있었습니다.

SKIA는 C++로 작성된 오픈소스 2D 그래픽 엔진 라이브러리입니다. 여러 플랫폼을 지원하기에, 크로스 플랫폼 프레임워크인 Flutter와 잘 궁합이 맞아 지금껏 친구 관계로 남아있었습니다.
그러나 SKIA는 지속적으로 Jank 문제를 겪고 있었다고 합니다. Jank는 그래픽 렌더링 엔진에서 겪는 치명적인 병목 성능 저하 이슈를 의미합니다. Slow Frame이라고도 하고, FPS가 순간순간 떨어지는 프레임 드랍 문제를 의미합니다.
예를 들어 60 FPS로 화면을 그리는 렌더링이 요구된다고 합시다. 이 경우 1초에 60개의 프레임을 화면에 그려내기 위해서, 1개의 프레임을 16ms 내에 처리해내야 합니다. 즉 1개 프레임을 그려내는데 16ms를 넘기게 되는 경우, UI Jank, 프레임 드랍이 발생하게 됩니다.
SKIA는 나름 이 고성능의 업무를 잘 수행하도록 설계되었지만, 그럼에도 불구하고 끊임없이 Jank에 대한 문제는 계속해서 이슈되었다고 합니다. Flutter로 개발된 Google Nust Hub, GPay 등에서 이 문제가 이슈로 생성되고 있었습니다.
결국 Flutter 팀은 칼을 빼들었고, 3.10부터 Impeller라는 엔진을 도입했습니다.

Impeller는 SKIA를 대체할 새로운 Flutter의 렌더링 엔진입니다. 현재는 iOS에 Default로 적용되어 있고, 혹시 적용되지 않았다면 Impeller로 바꾸는게 이득이라고 합니다.
Impeller는 폴리곤 기반의 SKIA 엔진과 렌더링 방법 자체부터가 다르다고 합니다. 이 부분은 공식 문서와 유튜브에서 자세한 정보를 찾을 수 있습니다.
또한 2D 그래픽 엔진인 SKIA와 다르게 Impeller는 3D까지 지원을 하고 있어, 앞으로 Flutter의 3D 지원이 더 강화될 것 같습니다.
Flutter Web
Flutter web 역시 빠질 수 없습니다. Flutter로 Web을 만들 수 있을까요? 사실 아직까지 프로덕트 레벨에서 만드는 것은 한계가 많은 것 같습니다. 발표자 분 역시 대놓고 Web이 나오자마자 한숨을 푹 쉬시면서 “문제가 많아요”하시는 게 인상 깊었습니다.
플러터 웹의 문제점으로 거론되는 것은 크게 네 가지가 있습니다.
- hot reload가 아닌 hot restart만 가능한 문제(#53041)
- SEO의 부재(#46789)
- SSR의 부재(#47600)
- main.dart.js is too large(#46589)
결론부터 말하면 이 문제들은 플러터의 구조상 해결되기가 쉽지 않아보입니다.
물론 최근에 Flutter의 구조상 Code push가 불가능하다고 말했던 과거 인식과 달리, Code push가 제3자 라이브러리를 통해서 제공된 것을 감안하면, 나중에 이 문제를 해결할 수 있는 방법이 등장할 지도 모르겠습니다. 그러나 현재 Flutter Web 팀은 다른 것에 집중을 하고 있는 것으로 보입니다.
바로 WASM(Web Assembly)입니다.

WASM은 웹상에서 컴파일 언어를 돌릴 수 있게 하는 기술입니다. 지금까지 브라우저에서는 표준 언어인 JavaScript 외에 다른 언어를 동작시키는 것은 어려운 행동이었습니다. 그러나 웹 어셈블리가 등장한 이유, 대표적으로 Rust가 프론트 프레임워크를 선보이면서 다른 언어들 역시 브라우저 상에 진출할 기회를 얻었습니다.
요새는 포토샵, 프리미어프로와 같은 무거운 어도비 프로그램을 컴퓨터에 설치하지 않고, 웹상으로 돌리기도 합니다. 이 무거운 C++로 작성된 데스크톱 프로그램을 어떻게 웹 브라우저 상에서 돌릴 수 있었을까요? 그것도 컴퓨터의 가용 자원을 사용하면서. WASM이 모든 것을 가능케 했습니다.
그러나 지금까지 WASM은 말 그대로 웹 어셈블리, 즉 어셈블리로 변환되는 수준의 언어만 지원했습니다. GC를 지원하지 않았습니다.
C/C++/Rust 등의 언어들은 WASM이 지원했지만, GC가 있어야 하는 언어인 Dart는 지원하지 못 했습니다.
그러나 Flutter 팀의 지속적인 노력으로, Web GC 기술에 힘입어 WASM에서 Dart를 돌릴 수 있게 됐다고 합니다.

이전의 Flutter Web은 Dart로 작성된 코드를 모두 JS 파일로 변환하는 형식으로 작동했습니다.

그러나 Flutter 3.10부터는, 일부 그래픽 엔진들은 wasm으로 작동합니다.
그러나 여전히 많은 Dart 코드들은 JS로 컴파일되어야 합니다.

플러터 팀의 궁극적인 목적은 모든 JS 파일들을 걷어내고, 이를 전부 WASM으로 교체하는 것입니다. 이 과정을 함께 지켜보는 것도 좋은 여정이 될 것 같습니다.

WASM과 WebGC는 미래의 얘기고, Flutter 3.10 Web 현재에서 바뀐 개선점은, CanvasKit의 성능 개선과 폰트 사이즈의 변화로 초기 로딩 속도가 비약적으로 상승하였다고 합니다.
실제로 발표자 분께서 테스트해본 결과 기존에 0.7초 정도 걸리던 로딩이 Flutter 3.10에 와서 0.3초 정도로, 비약적으로 성능이 상승되었다고 합니다. 다만 실제로 폰트 로딩같은 경우는 발표자 분이 직접 실험하니깐 그리 크게 안 바뀌었다고 하네요?
다만 JS 기반으로 만드는 것에 비하면 여전히 높지 못한 성능같기는 합니다. 아마 똑같은 앱을 JS로 만들면 로딩은 0.1초 이내로 끝날 것입니다. 1년 전 영상이기는 하지만, Flutter Web vs HTML, CSS & JS: Performance Comparison 영상에서 조금은 충격적인 비교 수치를 알 수 있습니다.
플러터 팀에서 절댓값을 보여주지 않고 상대적인 수치로만 비교하거나, 다른 JS와 성능 비교를 하지 않는 이유이기도 한 것 같습니다…
사실 현실은 상당히 회의적이고, 개발자들 사이에서 놀림거리이자 밈(Meme)이 되는게 플러터 웹의 현실이지만, 저는 플러터 웹 개발에 상당히 관심이 많습니다. 플러터는 여전히 발전 중인 프레임워크이고, 플러터 웹 역시 계속해서 발전해나가는 것을 지켜보는 것이 상당히 즐겁습니다. 꼭 플러터 웹이 성공해서 JS가 아닌 새로운 웹 시장의 프레임워크로 자리잡았으면 합니다.
한 가지 고무적인 것은 Web에서 Shader 지원이 한층 강화되었습니다.

https://youtu.be/HQT8ABlgsq0?t=2578
위 영상에서 보이는 매우 복잡한 3D 그래픽을 이제 Flutter로 구현할 수 있다고 합니다. 멋있습니다.
Flutter, Dart, and Raspberry Pi

정말 생각지도 못한 단어의 조합인데, 플러터에서 라즈베리파이도 지원한다는 사실 저만 몰랐나요..? 임베디드 기기 라즈베리파이 맞습니다.
제가 아두이노를 마지막으로 다룬 지가 6년이 넘었는데, 그때 C 언어로 열심히 하드 코딩해서 Hello World 수준으로 다룬 기억이 있습니다. 그리고선 완전히 잊고 살았는데, Flutter 발표에서 임베디드 기기가 나올 줄은 생각도 못 했습니다.

아니 근데 심지어 Flutter로 라즈베리파이 위에서 저런 게임도 만들어서 돌릴 수 있대요. 진짜 생각지도 못 했네요.
물론 라즈베리파이는 아두이노랑은 다른 개념으로, 자체적으로 리눅스도 올라가는 소형 데스크톱이긴 합니다. 그래서 리눅스를 공식 지원하는 Flutter이기에 안 될 것은 없지만, 조금 미스매치이긴 합니다.

이렇게 데스크톱이 아닌 컨트롤러로 작동하는 소프트웨어를 만들 때, 사용될 수 있다고는 합니다. 이걸 보니 사용처가 이해가 가긴 합니다. 닌텐도 비슷한 게임기를 만들 때, 플러터를 활용할 수도 있을 것 같습니다.
일단 그저 흥미롭고 놀라울 뿐입니다.
키워드: Flutter 3.10, Impeller, Dart 3, Flutter Web
Apache Airflow in Google Cloud
Airflow가 뭔지 모르는데 왜 이 아젠다를 들었냐구요? Google Cloud가 들어가 있으니 뭔가 도움이 될 줄 알았죠.. 그냥 넓고 시원한 401호에서 Go 언어를 들었으면 어땠을까 합니다.
그래도 발표가 끝난 이후 중요했던 키워드들을 위주로 기술들을 더 찾아보면서 새로운 공부가 되었습니다.
Airflow는 복잡한 워크플로우와 데이터 파이프라인을 조정하고 예약하는 데 사용되는 오픈 소스 플랫폼입니다. Airbnb에서 개발되었으며, Airflow란 이름 또한 Airbnb와 workflow를 합친 용어입니다. 이후에 Apache 재단에 인수된 이후로 쭉 Apache가 관리하고 있습니다.
뭔가 DaG, 인프라 스트럭처 등의 용어가 오간 것 같습니다. Airflow와 GCP를 이용해서 워크 플로우를 관리하는 방법을 상세한 코드와 함께 제공을 했습니다. 도커와 쿠버네티스의 세팅부터, GCE를 구동시키고 이를 Airflow pipeline에 포함시키는 것, Terraform, GKE Autopilot 등의 키워드도 기억에 남습니다.
아직 모르는 기술이 너무 많습니다. 열심히 배워야 할 것 같습니다.
알아듣지는 못 했지만 이런 내용들은 메모를 열심히 해두었습니다.
- 테라폼의 스크립트는 모두 멱등성을 보장하기에, 스크립트를 몇 번 실행하든 서버에 변화는 없다
- GCP에서 Terraform이 매우 깊숙히 연결되어 있음
- AWS의 Cloud Formation 등은 특정 벤더에 락인 효과, 그러나 Terraform은 Kubernetes 포함 여러 서비스를 모두 지원 → 락인 효과 방지 가능
- GKE Autopilor
- kubernetes를 서버리스로 운용하는 느낌
- 쿠버네티스 클러스트에 달려있는 노드를 관리할 필요 없음
- 간단한 설정 코드 작성하면 쿠버네티스 클러스트 생성이 끝이 나고, 그 위에 Airflow를 올린다
선택 가이드:
| Compute Engine(GCE) | Google Kubernetes Engine(GKE) | Google Composer |
|---|---|---|
| 저렴하고 쉽게 운영 가능합니다. 그리고 코드 배포가 쉽습니다. DAG 개수가 예측 가능하고 다운타임이 허용될 때 가볍게 돌리기에 적합합니다. 하지만 DAG에서 남는 로그를 정리하는 등 인스턴스 관리 리소스가 추가로 발생됩니다. | 기본적으로 Kubernetes에 대한 이해를 요구합니다. Autopilot으로 확장이 용이하고 가용성이 뛰어나지만 클러스터 기본 비용을 포함해서 비용이 비쌉니다. DAG 개수가 예상보다 빠르게 늘어나고 DAG에서 사용하는 컴퓨팅이 다양할 때 사용하기 좋습니다. | 완전 관리형 서비스로 Airflow 환경에 대한 이해가 적더라도 쉽게 운영이 가능합니다. 환경을 수정하는데 시간이 오래 걸립니다. 쉽게 고장나지 않지만 고장나는 경우 환경을 재배포해야 하는 수고가 필요합니다. |
일 잘하는 개발자는 회사에서 어떻게 일할까?
이 발표도 엄청 좋았던 발표입니다. 개인적으로 2순위입니다. 일 잘하는 개발자가 회사에서 어떻게 일할까요? 단순히 코딩만 잘 해서 잘 하는 개발자일까요? 아닐 것입니다.
이 발표에서는 비단 개발자 뿐만 아니라, 거의 대부분의 경우에서 적용될 수 있는 여러 가지 일 잘하는 조건을 이야기합니다.
저 역시 한 동아리의 운영진도 해보고, 다른 동아리의 회장 역시 수행하면서, 일을 잘 하는 것에 대해서 많은 고민을 하고 있습니다.
일을 잘하는 사람을 찾기란 정말 어렵습니다. 그만큼 일 잘하는 사람을 곁에 두려고 더 노력하지만, 일 잘하는 사람들이 제 곁에 있기 위해선 저 스스로 일을 잘 하는 사람이 되어야겠죠.
이 아젠다에서 말한 일 잘하는 개발자들의 특징 역시, 제가 경험했던 일을 잘하는 사람들의 특징과 일맥 상통합니다.
이 발표는 너무 좋았기에 별도의 포스트로 빼겠습니다. 다만 이 발표에서 소개한 일 잘하는 개발자의 조건을 요약하면 아래와 같습니다.
- 암묵지를 없애라 - 당연한 것들을 당연한 것으로 암묵적으로 받아들이지 않고, 이를 명목화한다
- 기술로만 문제를 해결하려고 하지 않는다 - 기술적인 방법보다 더 경제적인 방법을 찾는다
- ‘안된다’고 하지 않는다 - 대안을 제시한다
- 최적의 기능 개발 방향을 찾는다
- 모든 것을 기록한다
- 하라는 대로 하지 않는다 - 단순히 기획자가 시킨 일을 그대로 수행하지 않는다. 대신 더 나은 방향을 찾고 이를 역으로 제안한다
- 일정 공유 - 일정을 공유해서 상급자가 예측 가능하게 한다
- 혼자서 다 하려고 하지 않기 - 도움을 받아 훨씬 빠르게 일을 해결한다
- 인정할 줄 안다
- 명확한 단어와 문장 사용
- TODO/Reminder - 투두 리스트와 리마인더를 잘 활용한다
- 알아서 잘한다
- 귀찮아 한다 - 모든 것을 자동화하려고 한다
- 회고
종합 후기
작성을 하고 보니 후기보다는 발표 내용을 정리한 것에 가까워졌습니다.
Google은 개발자들을 위한 행사를 적극적으로 주최합니다. 구글의 문화는 많은 개발자들에게 영감이 되기도 합니다. 또한 이러한 지식 공유의 장이 더 적극적으로 늘어났으면 하는 바램입니다.
앞으로도 이런 자리 있으면 빠지지 않고 많이 가야겠습니다.
발표를 총평하자면…
- 세상의 모든 데이터베이스 이야기
- 데이터베이스에 대한 선택 가이드라인이 된 발표입니다.
- 내용 자체가 나열식이여서, 가벼운 발표였습니다.
- GCP 활용해서 Data Engineering 하기
- 키워드 중심으로 기술을 기억해 둔 뒤, 나중에 쓸 일이 생길 때 배우면 좋을 것 같습니다
- Flutter Clean Architecture
- 클린 아키텍처에 대해서 알 수 있어서 좋았습니다. 도움이 꽤 많이 됐습니다
- Flutter Google I/O 2023 Recap
- 나열식 발표이나, 발표자의 경험과 의견이 더해져서 가장 도움이 많이 됐습니다
- 워낙 잘 정리를 해주셔서 좋았습니다
- 일 잘하는 개발자는 회사에서 어떻게 일할까?
- 다년간의 경험이 녹아져 있는 발표였습니다
- 보고 배울 점이 많고, 적용이 가능한 점들도 많습니다