

논리적 데이터 모델링
논리적 데이터 모델링은, 개념적 데이터 모델링 단계에서 설계한 데이터 모델을 관계형 데이터베이스의 패러다임에 맞추어 옮기는 작업을 말한다.
논리적 데이터 모델링 단계에서 한 가지 중요한 유의점은, 이 과정에서는 구체적인 데이터베이스 제품을 선택하는 단계는 아니라는 점이며, 사양이나 성능 등의 문제는 신경쓰지 않는다.

논리적 데이터베이스 모델링 단계에서는 위와 같이, 개념적 데이터베이스 모델을 스키마 형태로 그린다. 위 사진이 데이터베이스 스키마의 한 예시이다.
Mapping Rule (매핑 룰)
개념적 데이터베이스 모델링의 결과를 관계형 데이터베이스 이론에 근거하여 데이터베이스 스키마로 변환하는 과정을 말한다.
- ▢ Entity → Table
- ○ Attribute → Column
- ◇ Relationship → PK, FK
요소(Entity)는 표(Table)로, 속성(Attribute)은 열(Column)으로, 관계(Relationship)은 표에서의 고유키(Personal Key), 외래키(Foreign Key) 관계로 변환한다.
Entity를 속성 별로 표로 전환하는 것은 비교적 쉽다. 그러나 관계에 따라서 외래키를 부여하고, 식별자를 부여하는 것이 다소 복잡할 수 있다. 각각 일대일, 일대다, 다대다 관계에 따라서 어떻게 처리를 할 지 살펴보자.
1대 1 관계 처리
1대 1 관계는 누구에게 FK를 줄 것인지만 정하면 된다.
예를 들어서 저자와 휴면저자에 대한 테이블이 서로 1대 1 관계라고 하자.
이때 누가 누구한테 의존하고 있는지를 따져보면 FK를 누구한테 줄 것인지 결정할 수 있다.
저자는 휴면 저자에 해당하는 행이 없어도, 스스로 존재할 수 있다.
휴면 저자는 저자 테이블에 해당하는 행이 없으면, 스스로 존재할 수 없다 (저자에 의존적임)
따라서 휴면 저자에게 FK를 주는 것이 맞다.
저자
| id | name | created_year |
|---|---|---|
| 1 | kim | 2018 |
휴면 저자
| fk_author_id | created_year |
|---|---|
| 1 | 2020 |
1대 N 관계 처리
N 쪽인 테이블에 FK를 주면 된다.
예를 들어 author : comment = 1 : N 관계라 하자. 즉 하나의 저자는 여러 개의 댓글을 가질 수 있다.
그리고 topic : comment = 1 : N 관계라 하자. 즉 하나의 주제(글)은 여러 개의 댓글을 가질 수 있다.
author
| id | name | profile | created_year |
|---|---|---|---|
| 1 | kim | developer | 2011 |
| 2 | lee | designer | 2012 |
topic
| id | title | description | created_year |
|---|---|---|---|
| 1 | MySQL | MySQL is … | 2012 |
| 2 | Oracle | Oracle is … | 2013 |
comment
| id | description | topic_id | author_id | created_year |
|---|---|---|---|---|
| 1 | MySQL is … | 1 | 1 | 2012 |
| 2 | Oracle is … | 2 | 2 | 2013 |
N대 M 관계 처리
별도의 매핑 테이블을 만들어서 처리한다.
author
| id | name | profile | created_year |
|---|---|---|---|
| 1 | kim | developer | 2011 |
| 2 | lee | designer | 2012 |
| 3 | park | planner | 2013 |
topic
| id | title | description | created_year |
|---|---|---|---|
| 1 | MySQL | MySQL is … | 2012 |
| 2 | Oracle | Oracle is … | 2013 |
| 3 | MSSQL | MSSQL is … | 2014 |
write
| author_id | topic_id | created |
|---|---|---|
| 1 | 1 | … |
| 1 | 2 | |
| 2 | 1 | |
| 2 | 3 |
위 테이블을 보자.
하나의 topic은 여러 개의 author를 가질 수 있고, 하나의 author은 여러 개의 topic을 가질 수 있다. 즉 topic : author = N : M 이다.
이때는 write라는 별도의 매핑 테이블을 만들어서 처리한다. 이때 Optionality도 살펴보자. topic이 있다면, write는 반드시 존재한다. write가 있다면 topic도 필수적이다. 즉 write (1..N) - (1) topic 관계이다.
한편 write가 있다면 author은 반드시 존재해야 하지만, author에게 topic이 존재할 필요는 없다. 따라서 Author에게 Topic은 Optional하므로, author (1) - (0..1) write 관계이다.
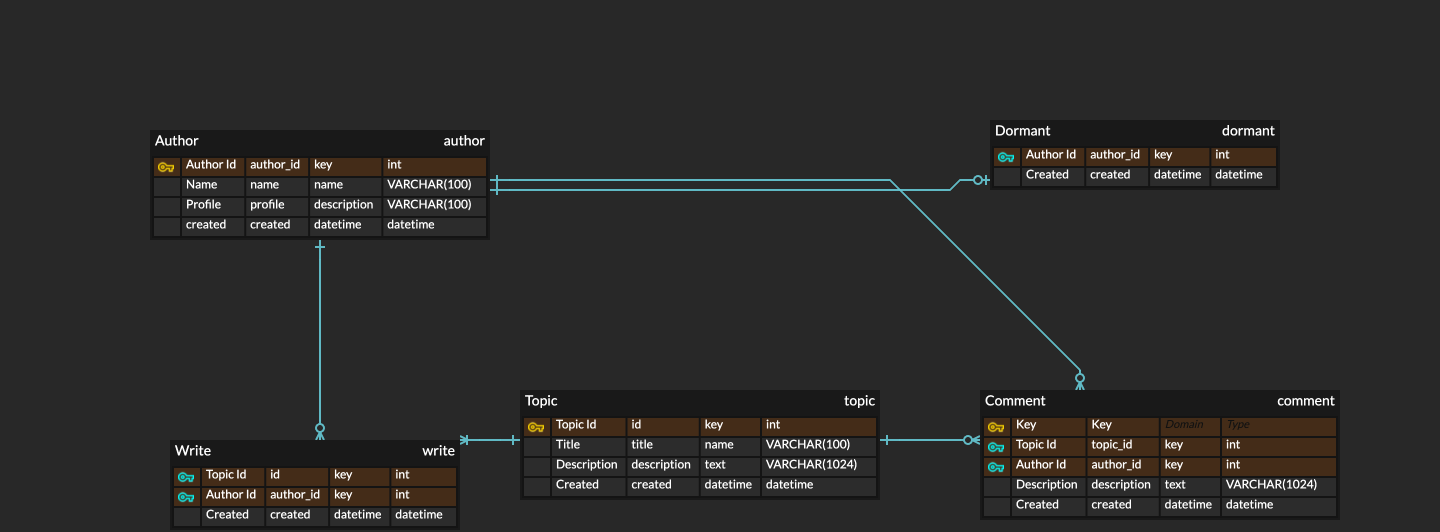
위 어플리케이션은 ERDCloud라는 DB 모델링 도구를 사용했는데, 굳이 ERDCloud 외에도 많은 더 좋은 도구들이 있으니 찾아서 사용하면 좋을 것 같다.
정규화
에드거 F. 커드 박사는 정제되지 않은 데이터(표)를 정제된 데이터 베이스로의 형태로 바꾸는 방법을 개발했다. 에드거의 1NF(제 1 정규형) 이후, 2NF, 3NF 등 많은 정규화 방법론이 개발됐다.
학술적으로는 6NF까지 존재하지만, 실무적으로는 3NF까지만 주로 사용한다.
정규화는 1NF, 2NF, 3NF 순서로 차근차근 진행하면 된다.
| 정규화 | UNF(비정규형) | 1NF | 2NF | 3NF |
|---|---|---|---|---|
| PK | ✅ | ✅ | ✅ | ✅ |
| No repeating group | ✅ | ✅ | ✅ | ✅ |
| Atomic columns | ❌ | ✅ | ✅ | ✅ |
| No partial dependencies | ❌ | ❌ | ✅ | ✅ |
| No transitive dependencies | ❌ | ❌ | ❌ | ✅ |
제1 정규화
Atomic columns
Each cell has a single value
모든 셀은 하나의 값 만을 가져야 한다.
고객들의 신용카드 사용 내역을 표현한 테이블을 가정하자. 이 테이블이 제 1정규화가 안 돼 있을 경우, 데이터 쿼리와 조작은 매우 복잡해진다.
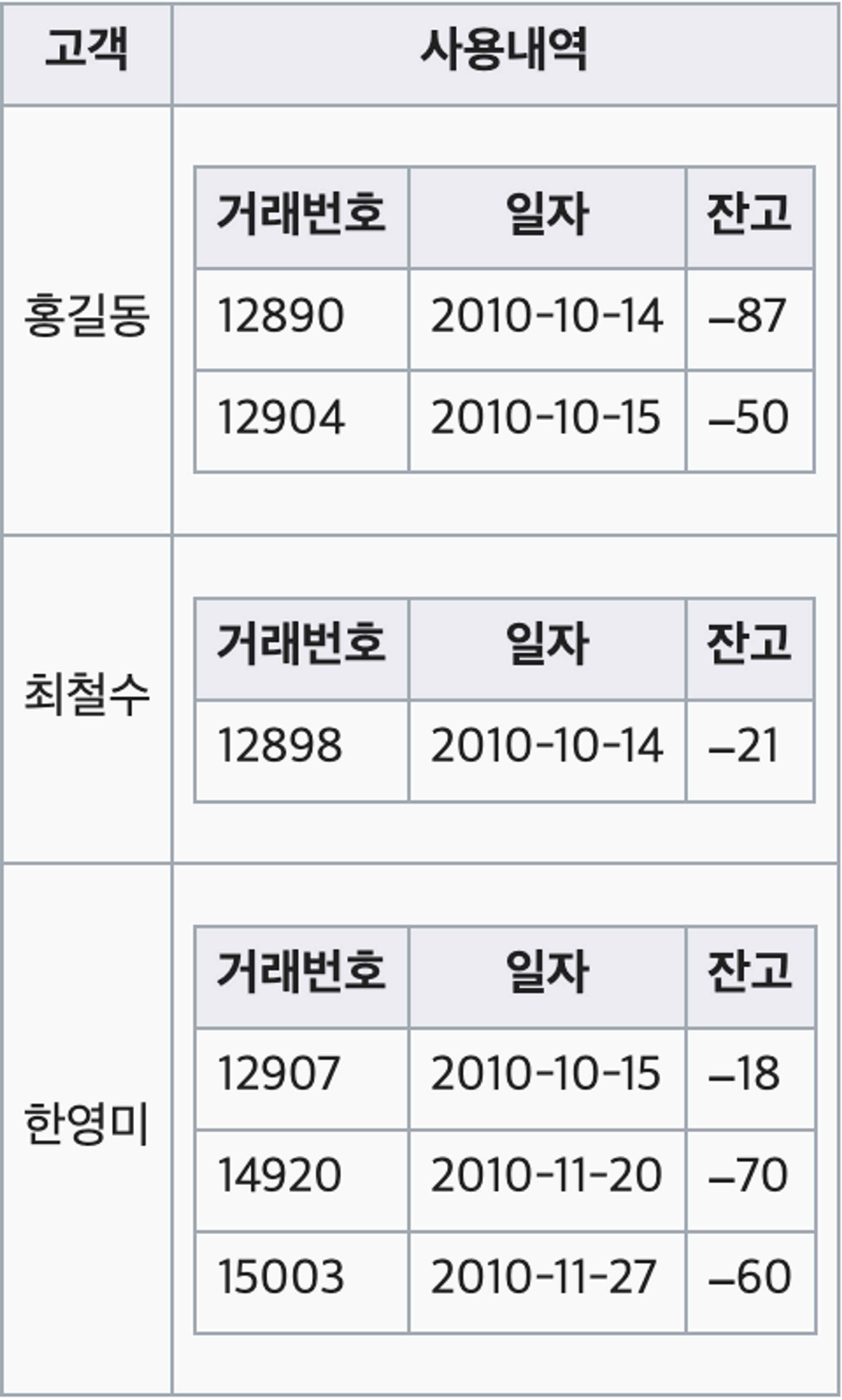
각 고객들마다 거래에 반복이 존재한다. 1NF은 각 컬럼이 Atomic, 즉 하나의 셀에 하나의 value만 들어갈 것을 요구한다.
이를 제1 정규화하면 아래와 같다.
| 고객 | 거래번호 | 일자 | 잔고 |
|---|---|---|---|
| 홍길동 | 12890 | 2010-10-14 | −87 |
| 홍길동 | 12904 | 2010-10-15 | −50 |
| 최철수 | 12898 | 2010-10-14 | −21 |
| 한영미 | 12907 | 2010-10-15 | −18 |
| 한영미 | 14920 | 2010-11-20 | −70 |
| 한영미 | 15003 | 2010-11-27 | −60 |
위 데이터는 모든 값이 동등한 구조를 가진다. 이전 구조에서는 하나의 셀에 하위 레벨의 표가 존재해, 별도로 쿼리문을 작성해야 했다.
예시를 더 보자.
| title | type | description | created | author_id | author_name | author_profile | price | tag |
|---|---|---|---|---|---|---|---|---|
| MySQL | paper | MySQL is ... | 2011 | 1 | kim | developer | 10000 | rdb, free |
| MySQL | online | MySQL is ... | 2011 | 1 | kim | developer | 0 | rdb, free |
| ORACLE | paper | ORACLE is ... | 2012 | 1 | kim | developer | 15000 | rdb, commercial |
빨간색 부분은 각각 중복이 발생하는 구간이다. tag 컬럼은 하나의 셀에 두 개의 값이 동시에 들어가 있다. 좋지 못한 구조이다. 우선 1NF를 통해 tag 컬럼을 atomic하게 바꾸어보자.
topic
| title | type | description | created | author_id | author_name | author_profile | price |
|---|---|---|---|---|---|---|---|
| MySQL | paper | MySQL is ... | 2011 | 1 | kim | developer | 10000 |
| MySQL | online | MySQL is ... | 2011 | 1 | kim | developer | 0 |
| ORACLE | online | ORACLE is ... | 2012 | 1 | kim | developer | 0 |
tag
| id | name |
|---|---|
| 1 | rdb |
| 2 | free |
| 3 | commercial |
topic_tag_relation
| topic_title | tag_id |
|---|---|
| MySQL | 1 |
| MySQL | 2 |
| ORACLE | 1 |
| ORACLE | 3 |
핵심은 topic_tag_relation 테이블인데, topic과 tag라는 다대다 관계를 연결하는 별도의 테이블을 만들어서, 1NF를 완성한다.
제2 정규화
No partial dependencies
values depend on the whole of every Candidate key
부분 종속성을 없애야 한다.
즉, 표에 중복키가 있다면 이를 제거하라.
제1 정규화 결과에서 topic 테이블을 다시 보자. 중복이 발생하고 있음을 알 수 있다.
topic
| title | type | description | created | author_id | author_name | author_profile | price |
|---|---|---|---|---|---|---|---|
| MySQL | paper | MySQL is ... | 2011 | 1 | kim | developer | 10000 |
| MySQL | online | MySQL is ... | 2011 | 1 | kim | developer | 0 |
| ORACLE | online | ORACLE is ... | 2012 | 1 | kim | developer | 0 |
이는 빨간색 부분의 컬럼이 바로 title 컬럼에 대해서만 부분 종속적이기 때문이다. 위 테이블의 식별자(PK)는 title과 type으로 구성된 복합키(Composite Key)로 구별된다.
그러나 중복이 발생하는 부분은 type과 상관 없이 오직 title 에게만 의존적이기에, 이런 문제가 발생한다.
위 상황이 왜 발생하게 됐냐 생각해보면, 바로 price 컬럼의 존재 때문이다. price는 title과 type 두 컬럼에 동시에 종속적이기에, 복합키를 요구한다. 즉 같은 title에 대해서 type이 paper냐 online이냐로 가격이 구분되므로, 중복이 발생한다.
이를 해결하는 방법은 부분 종속적인 컬럼들을 따로 분리하는 것이다.
topic
| title | description | created | author_id | author_name | author_profile |
|---|---|---|---|---|---|
| MySQL | MySQL is ... | 2011 | 1 | kim | developer |
| ORACLE | ORACLE is ... | 2012 | 1 | kim | developer |
topic_type
| title | type | price |
|---|---|---|
| MySQL | paper | 10000 |
| MySQL | online | 0 |
| ORACLE | online | 0 |
title과 type이라는 복합키에 종속적인 price는 따로 테이블을 분리하고, 오직 title 에 대해서만 종속적인 topic 테이블은 따로 분리한다.
제3 정규화
No transitive dependencies
values depend only on Candidate key
이행적 종속성을 제거하라.
| title | description | created | author_id | author_name | author_profile |
|---|---|---|---|---|---|
| MySQL | MySQL is ... | 2011 | 1 | kim | developer |
| ORACLE | ORACLE is ... | 2012 | 1 | kim | developer |
이 테이블을 다시 보자. 문제가 보이는가. 중복이 발생하고 있는데, 그 이유를 더 자세히 뜯어보자.
author_id는 분명히 title 에 종속적이다. 토픽을 쓴 저자는 분명히 서로 종속적인 관계를 갖는다.
그러나, author_name과 author_profile은 title에 종속적이지 않다. 이 두 컬럼은 author_id 에 종속적이다.
이처럼 한 테이블 안에 두 개의 종속성이 발생하는 것을 이행적 종속성이라고 한다. 위 예시에서는 description, created, author_id는 title 에 종속적인 반면 author_name, author_profile은 author_id에 종속적이다.
두 이행적 종속 관계를 가진 테이블을 나누자.
author
| author_id | author_name | author_profile |
|---|---|---|
| 1 | kim | developer |
topic
| title | description | created | author_id |
|---|---|---|---|
| MySQL | MySQL is ... | 2011 | 1 |
| ORACLE | ORACLE is ... | 2012 | 1 |
이렇게 하면 중복을 추가로 제거할 수 있다. author_id와 같은 FK는 중복이라고 치지 않는다.
이때 주의해야 할 것은, 위 예시는 author_id라는 확실한 종속 관계를 나타내는 identifier가 있었다. 그러나 author_id 없이 표가 아래와 같이 되어 있다고 하더라도, author_name과 author_profile은 분명 암시적으로 이행적 종속성을 띄고 있음을 알아챌 수 있어야 한다.
| title | description | created | author_name | author_profile |
|---|---|---|---|---|
| MySQL | MySQL is ... | 2011 | kim | developer |
| ORACLE | ORACLE is ... | 2012 | kim | developer |
이때는 두 컬럼을 분리하면서 새롭게 PK인 author_id 를 만들고, FK로 연결하면 된다.
사실 3NF은, ‘author’라는 prefix만 보더라도 직관적으로 종속성이 어디에 있는가를 알 수 있다. 우리의 직관이 움직이는 방향으로 나아가다 보면, 의식적으로 생각하지 않더라도 정규화의 과정을 완료할 수 있을 것이다.
결론
| title | type | description | created | author_id | author_name | author_profile | price | tag |
|---|---|---|---|---|---|---|---|---|
| MySQL | paper | MySQL is ... | 2011 | 1 | kim | developer | 10000 | rdb, free |
| MySQL | online | MySQL is ... | 2011 | 1 | kim | developer | 0 | rdb, free |
| ORACLE | paper | ORACLE is ... | 2012 | 1 | kim | developer | 15000 | rdb, commercial |
처음의 UNF 표와, 3NF까지 끝낸 결과를 비교해보자.
author
| author_id | author_name | author_profile |
|---|---|---|
| 1 | kim | developer |
topic_type
| title | type | price |
|---|---|---|
| MySQL | paper | 10000 |
| MySQL | online | 0 |
| ORACLE | online | 0 |
tag
| id | name |
|---|---|
| 1 | rdb |
| 2 | free |
| 3 | commercial |
topic
| title | description | created | author_id |
|---|---|---|---|
| MySQL | MySQL is ... | 2011 | 1 |
| ORACLE | ORACLE is ... | 2012 | 1 |
topic_tag_relation
| topic_title | tag_id |
|---|---|
| MySQL | 1 |
| MySQL | 2 |
| ORACLE | 1 |
| ORACLE | 3 |
더 직관적인가? 다이어그램 상에서 각 테이블 간의 관계가 명확해지고, 쿼리 문을 작성할 때 복잡성을 더 줄일 수 있다.
Reference
- 관계형 데이터 모델링, 생활코딩, 2019
- 데이터베이스 정규화, 위키피디아, 2023