

개념적 데이터 모델링
개념적 데이터 모델링이란?
업무라는 복잡한 현실속 문제에서, 특징을 추출하여 개념적인 데이터 모델을 세우는 작업이다. 업무와 논리적 데이터 모델링 단계를 연결하는 가교 역할을 하지만, 사실 개념적 데이터 모델링이 데이터 모델링의 절반 이상을 먹고 들어간다고 볼 수 있다. 이 단계에서 개념적 데이터 모델을 잘 설계한다면, 이후의 단계는 그냥 개념적 데이터 모델을 차근차근 컴퓨터 레벨로 옮기는 작업이기 때문이다.
개념적 데이터 모델링을 하는 이유이자 장점은 크게 두 가지가 존재한다.
- 현실에서 필요한 정보를 추출하는 필터의 역할
- 개념에 대해서 다른 사람과 대화할 수 있게 하는 언어의 역할
우리가 복잡한 현실을 모방할 때, 우리에게 필요한 정보만을 추출하고, 나머지 불필요한 부수적인 정보들은 걸러내야 한다. 그래야 개념이 명확해지고 만들고자 하는 모델이 단순해진다. 개념적 데이터 모델링 단계에서 정보를 추출하고 필터링하는 과정을 거친다.
그리고 이 단계에서 개념적 데이터 모델이 만들어지고 나면, 앞으로의 개발 과정에서, 개념에 대한 의사소통이 매우 명확해진다. 이 과정에서 업무에 대한 개념을 명확히 정의하기 때문에, 개발 과정에서의 혼선을 줄이는 언어로의 역할을 수행한다.
ERD (Entity Relationship Diagram)
ERD, 혹은 ER 다이어그램이라 불리는 것들이 있다.


이전 업무 파악 단계에서 파악된 업무를 오른쪽 그림과 같이 다이어그램 형태로 정리하는 것을 말한다. ERD는 현실을 세 가지 관점에서 바라볼 수 있게 해주는 파인더를 제공한다.
- 정보(Information): ERD는 정보를 발견하고 이를 표현할 수 있게 해준다.
- 그룹(Group): 서로 연관된 정보를 그룹핑하고 이를 표현할 수 있게 해준다.
- 관계(Relationship): 정보 그룹 사이 관계를 형성하고 이를 표현할 수 있게 해준다.
정보는 ERD에서 원으로 표시되고, 그룹은 사각형, 관계는 삼각형으로 표시된다.
ERD의 가장 큰 장점은, 바로 다이어그램을 매우 쉽게 표로 전환 가능하다는 점에 있다.
ERD를 그릴 수 있는 사이트는 사실 무수히 많은데, 생활 코딩 강의에서 소개된 사이트는 위 링크이다.
위 링크 외에도 Google에서 만든 Miro, Lucidchart 등 굉장히 많은 제품이 있다.
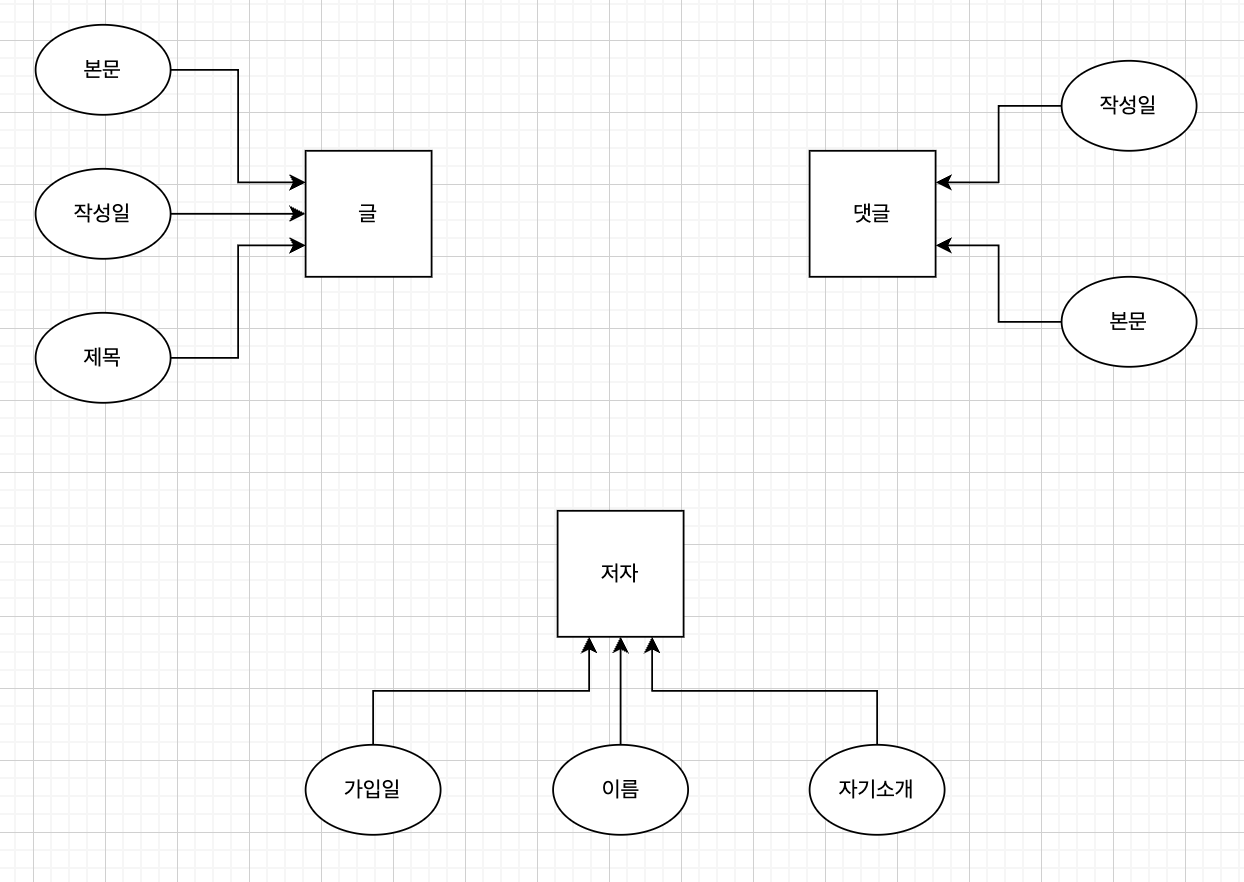
관계형 데이터베이스다운 개념의 구조

현실에서의 관점에서, 글과 댓글, 저자에 대한 구성은 위와 같이 생각해볼 수 있겠다. 그러나 관계형 데이터베이스에서는 위와 같은 내포 구조를 허용하지 않는다.
저렇게 모델링을 하게 된다면, 댓글이 작성될 때마다 컬럼이 수평적으로 확장되어야 하고, 각 셀의 값들이 계층화되어, 데이터를 다루는 쿼리문을 작성하는 것이 매우 복잡해질 것이다.
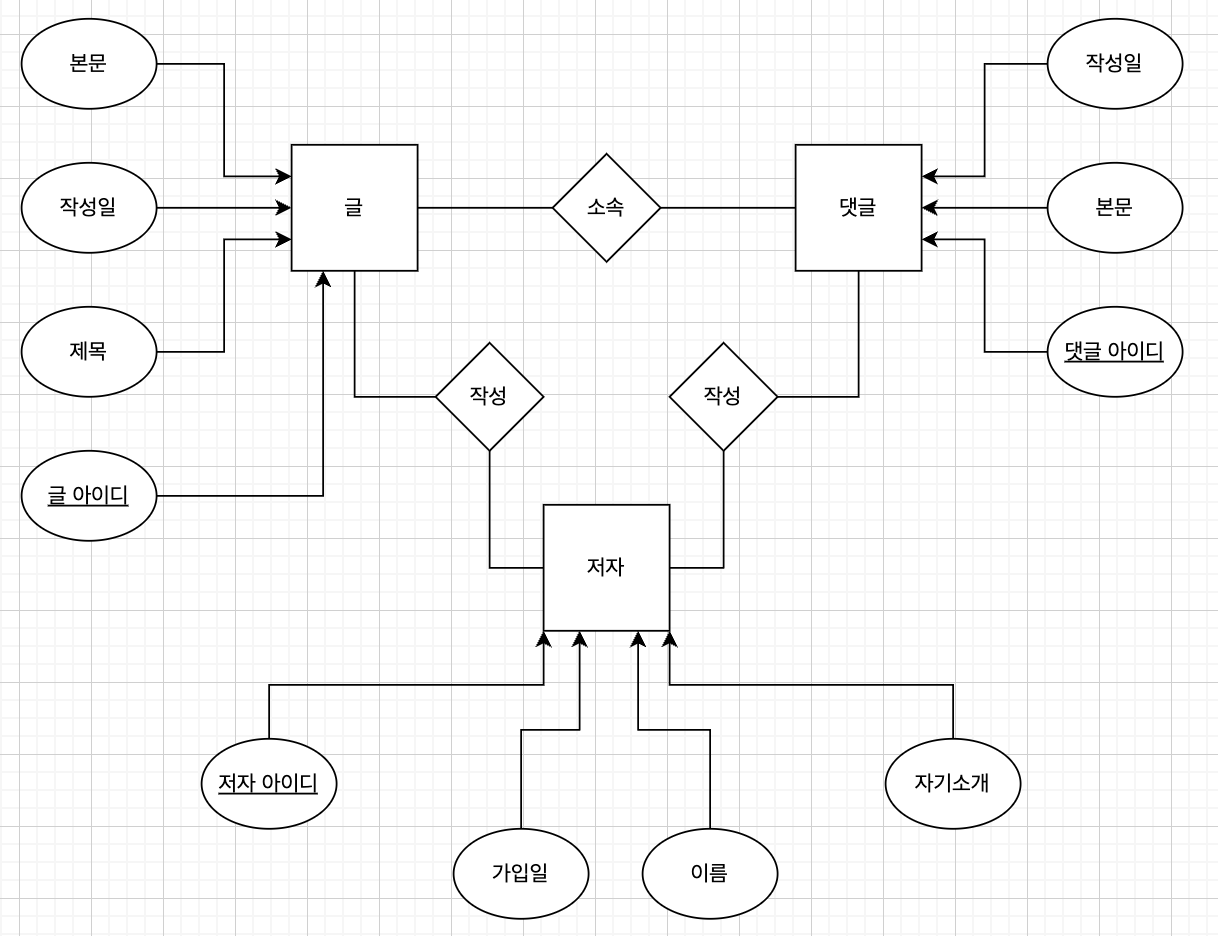
관계형 데이터베이스를 모델링할 때는 아래 도표와 같이 각 요소(Entity)별로 모델링을 하는 것이 일반적이다.
글
| 아이디 | 제목 | 내용 | 저자 아이디 |
|---|---|---|---|
| 1 | 제목 1 | 내용 1 | 1 |
| 2 | 제목 2 | 내용 2 | 1 |
| 3 | 제목 3 | 내용 3 | 1 |
저자
| 아이디 | 이름 | 소개 |
|---|---|---|
| 1 | 이름 1 | 소개 1 |
| 2 | 이름 2 | 소개 2 |
| 3 | 이름 3 | 소개 3 |
댓글
| 아이디 | 제목 | 내용 | 작성일 | 저자 아이디 |
|---|---|---|---|---|
| 1 | 제목 1 | 내용 1 | 작성일 1 | 1 |
| 2 | 제목 2 | 내용 2 | 작성일 2 | 1 |
| 3 | 제목 3 | 내용 3 | 작성일 3 | 2 |
위와 같이 테이블을 두면, 필요할 때마다 JOIN을 통해서 분리된 테이블을 합치게 된다.
SELECT
댓글.내용 AS "댓글 내용",
댓글.작성일 AS "댓글 작성일",
저자.이름 AS "저자",
저자.소개 AS "저자 소개"
FROM 댓글
JOIN 저자 ON 댓글."저자 아이디" = 저자."아이디"| 댓글 내용 | 댓글 작성일 | 저자 | 저자 소개 |
|---|---|---|---|
| 내용 1 | 작성일 1 | 이름 1 | 소개 1 |
| 내용 2 | 작성일 2 | 이름 1 | 소개 1 |
| 내용 3 | 작성일 3 | 이름 2 | 소개 2 |
ERD의 구성요소
ERD는 다음 세 가지로 구성된다.
- Entity → Table
- Attribute → Column
- Relation → PK, FK
Entity
위 사이트에서 ERD를 그릴 수 있다.
기획서에서 가장 먼저 해야 할 일은 Entity(속성, 엔티티)를 찾아내는 것이다. 사람은 Entity를 찾아낼 수 있는 탁월한 능력을 갖고 있다. 개별 특성을 찾아내서 Entity를 찾아낸다.
ER Diagram에서 Entity는 직사각형을 사용한다.

Attribute
속성은 각 엔티티가 갖고 있는 속성들을 의미한다. ERD에서는 타원으로 표기한다.
Identifier
Attribute를 정의했다면, 이제 식별자(Identifier)를 정의해야 한다. 식별자는 중복을 불허하고, PK로 사용된다.
식별자로 사용 가능한 키들의 후보를 후보키(Candidate key)라고 한다. user_id, email, natinal_id
등이 될 수 있다.
식별자는 user_id 등과 같이 인조키를 선택할 수도 있고, 복수의 컬럼을 동시에 묶어서 복합키(Composite key)로 활용할 수도 있다.
한편 email, national_id 와 같이 PK는 되지 않았으나 대체키(Alternative key)로 활용할 수 있는 것들은 후에 인덱싱에서 사용되기도 한다.
| user_id | national_id | name | city | |
|---|---|---|---|---|
| 1 | a@mail.com | 100001 | egoing | seoul |
| 2 | b@mail.com | 100002 | leezche | jeju |
| 3 | c@mail.com | 100003 | egoing | jeju |
아래는 복합키의 예. 직원 번호(emp_no)와 부서 번호(dept_no)는 각각은 중복이 발생하여 식별자로 사용할 수 없지만, 이 둘의 조합이 절대 중복이 발생하지 않는다면 복합키로 사용 가능하다.
| emp_no | dept_no | from_date (부서 배정일) |
|---|---|---|
| 1 | 1 | 2010 |
| 2 | 1 | 2011 |
| 1 | 2 | 2013 |
참고로 이러한 복합키는 N:M 관계(다대다 관계)에서 중간 연결 테이블을 만들 때, 연결 테이블의 식별자로 자주 사용된다.
Identifier는 ERD에서 밑줄로 표시된다.
Relationship
각 Entity를 연결하는 관계를 정의한다. 관계형 데이터베이스에서는 FK와 PK를 연결하는 것을 통해서 실제로 구현된다.
ERD에서는 마름모 꼴로 관계를 표시한다.

Cardinality와 Optionality
Cardinality는 쉽게 말해 전체 행에 대한 특정 컬럼의 중복도를 나타내는 지표이다.
- 중복도가 ‘낮으면’ Cardinality가 ‘높다’고 표현한다.
- 중복도가 ‘높으면’ Cardinality가 ‘낮다’고 표현한다.
정확히 따지면 Cardinality는 집합의 ‘원소 개수’에 대한 척도이다.
‘담임은 한 반만 담당한다고 했을 때’ 아래 예시를 보자.
| 담임 | 반 |
|---|---|
| kim | 1 |
| lee | 2 |
| park | 3 |
위의 예시에서는 담임과 반은 1:1 관계이다. 담임은 반을 하나만 맡을 수 있기 때문이고, 반은 하나의 담임만 갖고 있기 때문이다.
ERD에서는 선으로 표시한다.

또한, 담임과 반은 서로가 서로에게 항상 존재해야 한다. 따라서 필수적이다. 필수적인 것은 선 끝에 I 자 선을 그려 표시한다.

아래 예시를 또 보자.
| 댓글 | 저자 |
|---|---|
| 댓글1 | kim |
| 댓글2 | kim |
| 댓글3 | park |
각 댓글은 단 하나의 저자만 존재한다. 그러나 저자는 다수의 댓글을 가질 수 있다. 이러한 관계를 1:N 관계(일대다 관계)라고 한다. ERD에서는 삼지창 모양으로 표시를 하거나, (0..N), (1..N) 등으로 표시한다.
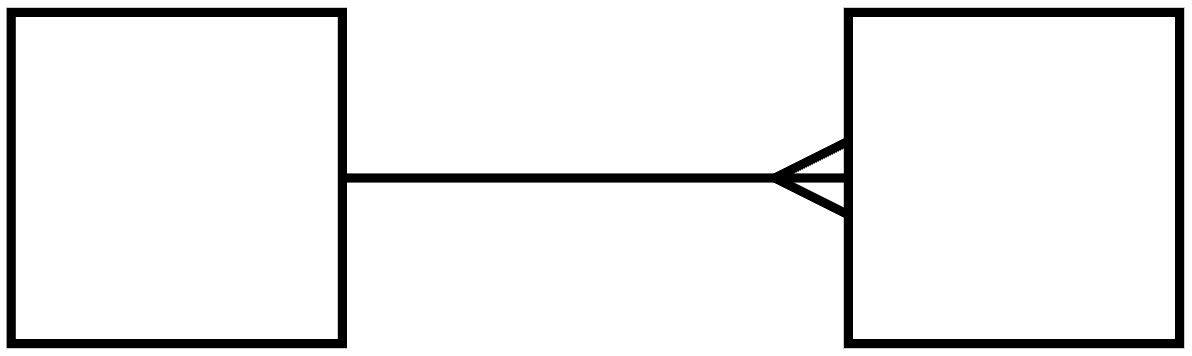
한편, 댓글은 반드시 저자를 가져야 한다. 그러나 저자는 0개의 댓글을 가질 수도 있다 (0..N). 따라서 댓글은 저자에게 선택적(Optional)이다. 반대로 저자는 댓글에게 필수적(Mandatory)이다.
즉 저자 (1) - (0..N) 댓글 관계이다.

이번에는 저자와 글의 관계를 보자.
우리가 만드는 시스템이 하나의 글은 복수의 저자를 둘 수 있다고 가정하자(나무위키 문서는 복수의 저자를 갖는다.). 한편 하나의 저자는 복수의 글을 가질 수 있다. 이러한 관계를 N:M 관계(다대다 관계)라고 한다.
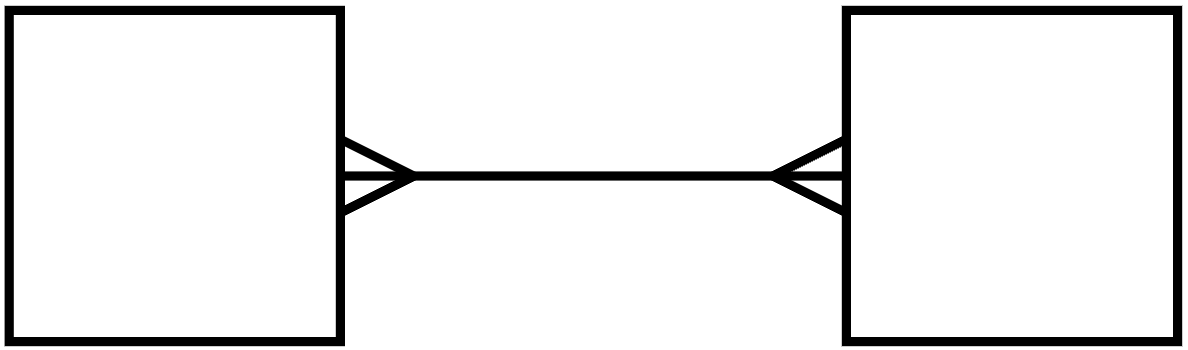
또한, 글은 반드시 하나 이상의 저자를 가져야 한다. 즉 저자 (1..N) - (0..N) 글의 관계이다.
따라서 아래와 같이 표시할 수 있다.

위 개념으로 ERD를 완성하면 아래와 같다.
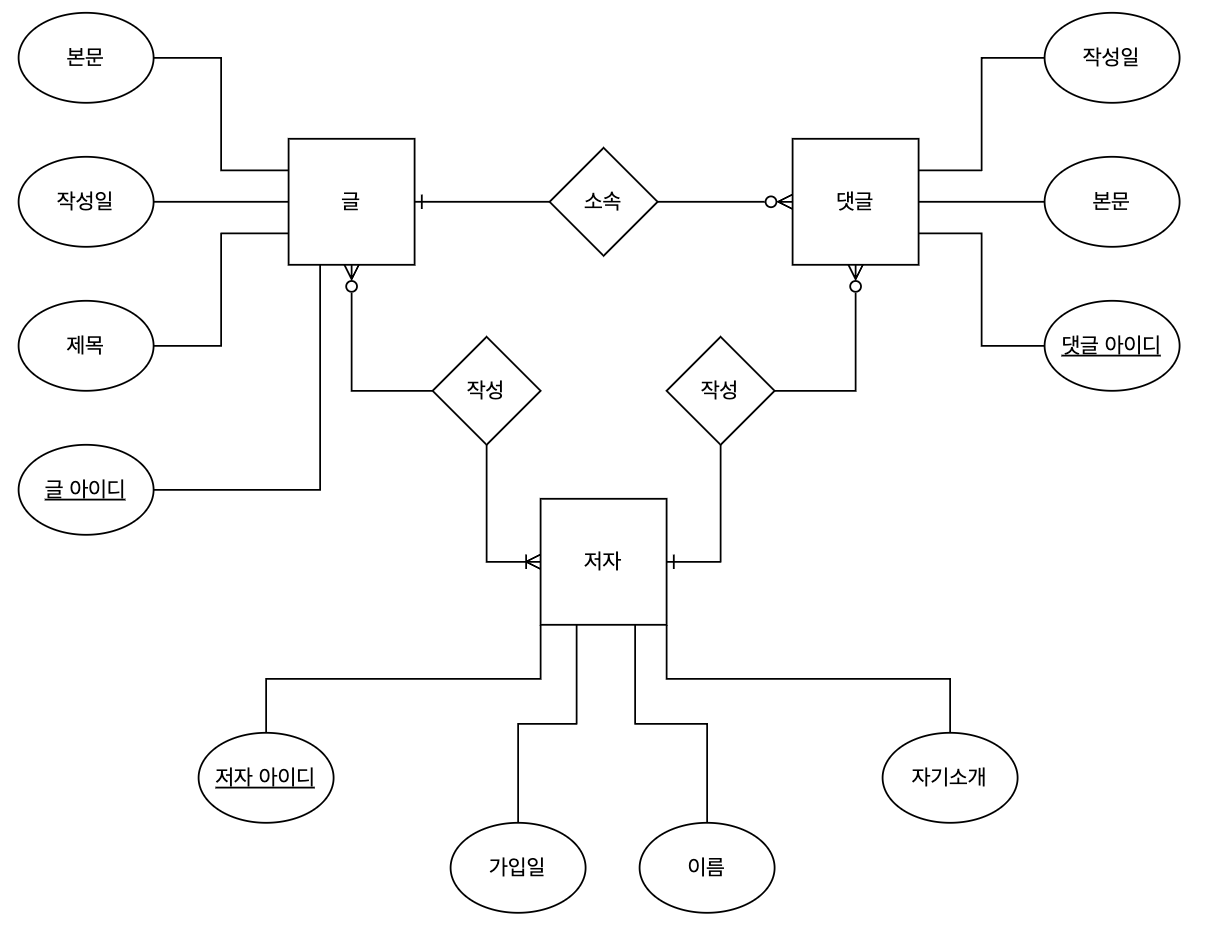
📚 핵심 정리
개념적 데이터 모델링은 업무로부터 개념을 추출하는 역할을 하며, ERD를 통해 개념을 명세화한다. ERD는 정보를 추출하는 필터 역할, 개념을 정의하는 언어 역할을 한다.
Reference
- 관계형 데이터 모델링, 생활코딩, 2019