

본 글은 갖고노는 MySQL 데이터베이스 by 얄코 강의를 수강하고 이를 정리한 글입니다.
식별자와 인덱스
PK, Unique, FK (기본키, 고유키, 외래키)
1. 기본키(Primary Key, PK)
- 중복되지 않는 고유값
NOT NULL- PK는 테이블 당 하나만 있어야 함
-- 기본키 넣는 방법 1
CREATE TABLE people (
first_name CHAR(2) **PRIMARY KEY**,
last_name CHAR(3),
nickname VARCHAR(10)
);
-- 기본키 넣는 방법 2
CREATE TABLE people (
first_name CHAR(2),
last_name CHAR(3),
nickname VARCHAR(10),
**PRIMARY KEY (first_name)**
);PK를 변경하려면
ALTER TABLE people DROP PRIMARY KEY;
ALTER TABLE people ADD PRIMARY KEY (last_name);다중 PK
PK는 단일 컬럼에 대해서만 설정할 수 있는 것이 아니라, 복수의 컬럼에 대해서도 설정할 수 있다.
CREATE TABLE people (
first_name CHAR(2),
last_name CHAR(3),
nickname VARCHAR(10),
**PRIMARY KEY (first_name, last_name)**
);이 경우 first_name, last_name이 각각 겹치는 것은 상관하지 않으나, 두 조합이 겹치는 것은 허용하지 않는다.
2. 고유키(Unique)
- 중복 불가
- NULL 가능함
-- 고유키 넣는 방법 1
CREATE TABLE people (
person_id INT AUTO_INCREMENT PRIMARY KEY,
**first_name CHAR(2) UNIQUE,**
last_name CHAR(3)
);
-- 고유키 넣는 방법 2
CREATE TABLE people (
person_id INT AUTO_INCREMENT PRIMARY KEY,
first_name CHAR(2),
last_name CHAR(3),
**UNIQUE (first_name)**
);
-- 다중 고유키
CREATE TABLE people (
person_id INT AUTO_INCREMENT PRIMARY KEY,
first_name CHAR(2),
last_name CHAR(3),
**UNIQUE (first_name, last_name)**
);3. 외래키(Foreign Key, FK)
외래키를 추가하려면 아래와 같이 한다.
ALTER TABLE _자식테이블명
ADD CONSTRAINT _제약명
FOREIGN KEY ( _자식테이블외래키 )
REFERENCES 부모테이블명 ( _부모테이블기본키 )
-- ON DELETE _삭제시제약
-- ON UPDATE _수정시제약외래키를 삭제하려면 아래와 같이 한다.
ALTER TABLE _자식테이블명 DROP FOREIGN KEY _자식테이블외래키FK 제약
| 제약 | 설명 | 비고 |
|---|---|---|
| NO ACTION, RESTRICT | 자식 테이블에 해당 외래키가 있을 때 수정/삭제되지 않음 | |
| CASCADE | 자식 테이블의 해당 행도 수정/삭제 | |
| SET NULL | 자식 테이블의 외래키를 NULL로 | 자식 외래키가 NOT NULL일 시 설정 불가 |
| SET DEFAULT | 자식 테이블의 외래키를 기본값으로 | InnoDB 엔진에서 사용 불가 |
외래키는 보통 제약과 함께 동반되는 경우가 많으니 (잘못된 FK를 자식 테이블이 갖지 않도록 하기 위해서) FK 제약은 필요할 때마다 찾아보자.
인덱스
1. Index 사용하기
인덱스의 개념을 알기 좋은 자료들
-- 인덱스 생성
ALTER TABLE `mydatabase`.`businesses`
ADD INDEX index_biz_name (business_name);
-- 다중 컬럼 인덱스
ALTER TABLE menus
ADD INDEX index_name_cal (menu_name, kilocalories);
-- 인덱스 조회
SHOW INDEX FROM businesses;
-- 인덱스 삭제
ALTER TABLE businesses
DROP INDEX index_biz_name;2. Index를 사용하기 적합한 곳
- 데이터의 변경이 잦지 않은 테이블
- WHERE, ORDER BY 에 자주 사용되는 컬럼
- JOIN에 사용되는 컬럼
- ⭐ Cardinality가 높은 컬럼 = 중복도가 낮은 컬럼 (B-Tree 경우)
- 성별: 부적합, 이름: 적합
- 성별의 경우에는 남자, 여자 밖에 없으니, 중복도가 높다고 할 수 있다(=Cardinality가 낮다)
- 반대로 이름의 경우에는 동명이인이 있을 수 있으나, 겹치는 게 적기에 중복도가 낮다고 할 수 있다(=Cardinality가 높다)
3. Index 종류
- B-tree Index
- Default Index
- Cardinality가 높은 컬럼에 적합하다
- Full Text Index
- 다수의 단어 등을 포함하는 컬럼에서 단어 및 구문을 검색하기 위함
- 데이터를 일정 단위로 분할하여 인덱싱
- _InnoDB, MyISM_에서만 사용 가능
- CHAR, VARCHAR, TEXT 컬럼에만 적용 가능
- Full-Text Index 문서 링크
- 다수의 단어 등을 포함하는 컬럼에서 단어 및 구문을 검색하기 위함
- 데이터를 일정 단위로 분할하여 인덱싱
- _InnoDB, MyISM_에서만 사용 가능
- CHAR, VARCHAR, TEXT 컬럼에만 적용 가능
- Full-Text Index 문서 링크
ALTER TABLE ratings
ADD FULLTEXT INDEX index_full_text (comment);
SELECT * FROM ratings
WHERE MATCH(comment) AGAINST ('괜찮은데');- Hash Index
- 일치 여부만 확인 (= 가능, >, >=, <, <=, LIKE 등 불가)
- 인덱스 크기가 작고 검색이 매우 빠름
- MEMORY, NDB 엔진에서만 사용가능
- InnoDB 엔진에서는 내부적으로 Adoptive Hash Index 구현
- 자주 사용되는 데이터만 내부적으로 해시값 생성하여 속도 증가
- Adoptive Hash Index 문서 링크
- InnoDB 엔진에서는 내부적으로 Adoptive Hash Index 구현
SQL 더 알아가기
1. View - 가상의 테이블
-- 뷰 생성
CREATE VIEW section_view AS
SELECT section_id, section_name
FROM sections;
-- 뷰 조회
SELECT * FROM section_view;
-- 뷰 삭제
DROP VIEW section_view;뷰를 사용하는 이유
- 보안: 테이블 구조 및 내용을 숨기기 위해
CREATE VIEW menu_view AS
SELECT
menu_id,
menu_name,
CONCAT(
SUBSTRING(business_name, 1, 1),
REPEAT('*', CHAR_LENGTH(business_name) - 1)
) AS business,
price,
likes AS evaluation
FROM businesses B
INNER JOIN menus M
ON M.fk_business_id = B.business_id;| menu_id | menu_name | business | price | evaluation |
|---|---|---|---|---|
| 1 | 물냉면 | 북*** | 8000 | 3 |
| 2 | 아메리카노 | 달** | 4500 | 6 |
| 3 | 고르곤졸라피자 | 커**** | 12000 | 12 |
| 4 | 보쌈 | 보**** | 14000 | 2 |
| 5 | 장국 | 할**** | 8500 | -1 |
- 편의: 복잡한 쿼리를 사전에 구현
아래와 같은 매우 복잡한 쿼리를 자주 사용해야 한다면, 이를 미리 구현하여 옮겨놓은 뷰를 사용하는 게 더 유리할 수 있다.
CREATE VIEW business_view AS
SELECT
section_name,
business_name,
(SELECT COUNT(*) FROM menus M
WHERE M.fk_business_id = B.business_id
) AS menu_count,
(SELECT AVG(likes) FROM menus M
WHERE M.fk_business_id = B.business_id
) AS menu_avg_likes,
(SELECT AVG(stars) FROM ratings R
WHERE R.fk_business_id = B.business_id
) AS avg_stars,
(SELECT comment FROM ratings R
WHERE R.fk_business_id = B.business_id
ORDER BY created DESC LIMIT 1
) AS recent_comment
FROM businesses B
INNER JOIN sections S
ON S.section_id = B.fk_section_id;| section_name | business_name | menu_count | menu_avg_likes | avg_stars | recent_comment |
|---|---|---|---|---|---|
| 중식 | 화룡각 | 2 | 17.5000 | ||
| 분식 | 철구분식 | 2 | 5.5000 | 4.0000 | 치떡이 진리. 순대는 별로 |
| 양식 | 얄코렐라 | 0 | |||
| 분식 | 바른떡볶이 | 2 | 0.5000 | ||
| 한식 | 북극냉면 | 2 | 3.5000 | 3.0000 | 육수는 괜찮은데 면은 그냥 시판면 쓴 것 같네요. |
내용 수정이 가능한 뷰
아래 조건을 하나라도 만족한다면 그 뷰는 수정이 불가능하다.
- 집계함수 사용하지 않음(MAX, MIN, AVG...)
- GROUP BY 사용하지 않음
- UNION, DISTINCT 사용하지 않음
- SELECT절에 서브쿼리 없음
- WHERE절의 서브쿼리가 FROM절의 테이블 참조하지 않음
- 조인은 INNER만 가능
-- 가능
UPDATE section_view
SET section_name = '서양식'
WHERE section_id = 5;
-- 가능
UPDATE menu_view
SET price = price + 1000
WHERE menu_name LIKE '%냉면';
-- 불가
UPDATE business_view
SET business_name = '화룡반점'
WHERE business_name = '화룡각';
-- business_view는 단순한 테이블의 뷰가 아닌, AVG, 서브 쿼리 등이 포함된 복합 뷰이다당연하지만 수정이 가능한 뷰여도, 원본 사용자가 권한을 허용해줘야지 뷰에 수정 권한이 생긴다.
2. Transaction - 원자성 부여(Atomic)
원자성이라 함은 일반적으로 무결성을 중요시하는 프로그래밍에서 자주 사용되는데, 쉽게 말해 전부 성공 or 전부 fail을 의미한다.
원자성이라 함은 더 이상 쪼개지지 않는 성질을 의미한다. 그 안에서 일부는 성공(1)하고 일부는 실패(0)하는 일이 없도록, 원자성을 부여해서 전체 성공 or 전체 실패의 결과만 있게끔 과정을 원자화하는 것이다.
은행의 트랜잭션 과정을 생각해보자. Amy가 Brian에게 1$를 송금했을 때 중간에 에러가 발생하였다. 이때 이 과정 전체가 실패했다면 문제가 되지 않는다. 다시 트랜잭션을 시도하면 되기 때문이다. 그러나 Amy가 1$를 송금한 트랜잭션은 성공하고, Brian이 1$를 송금받은 트랜잭션이 실패한다면 문제가 복잡해진다.
원자성이란, 이 송금 과정을 더 이상 쪼개지지 않는 단위로 설정해서, 일부만 성공하고 일부만 실패하는 일 없이, 전체를 한 덩어리로 묶는 과정을 말한다.
ROLLBACK
-- 트랜잭션 시작
START TRANSACTION;
DELETE FROM sections
WHERE section_id > 0;
SELECT * FROM sections;
-- 롤백
ROLLBACK;
SELECT * FROM sections;SQL에서는 ROLLBACK 을 통해서, 최초 트랜잭션 시작 포인트로부터 모든 기록들을 되돌릴 수 있다.
트랜잭션의 기본적인 원리는 모든 작업을 메모리(RAM) 위에서만 진행한다는 것이다. COMMIT 이전까지는 하드 드라이브에 저장하지 않고, 메모리 위에서만 작업을 진행한다.
COMMIT
램 위에서 진행된 작업을 파일로 저장하는 것이 COMMIT이다.
START TRANSACTION;
INSERT INTO sections
(section_name, floor)
VALUES ('동남아', 2);
SELECT * FROM sections;
-- 커밋, 작업 내용 저장
**COMMIT;**
ROLLBACK;
SELECT * FROM sections;위와 같이 COMMIT을 한 순간, ROLLBACK을 하여도 ‘동남아’, 2 라는 INSERT 구문은 실행이 된 것을 확인할 수 있다.
SAVEPOINT
롤백할 중간 세브 포인트를 지정할 수 있다. 이때는 ROLLBACK TO ... 이런 식으로 세이브 포인트로 돌아갈 수 있다.
START TRANSACTION;
INSERT INTO sections
(section_name, floor)
VALUES ('인도식', 2);
**SAVEPOINT indian;**
INSERT INTO sections
(section_name, floor)
VALUES ('남미식', 3);
SELECT * FROM sections;
**ROLLBACK TO indian;**
SELECT * FROM sections;
COMMIT;3. 사용자간 권한 다루기
1. 사용자
MySQL과 같은 RDBMS를 다룰 때는, 혹은 RDBMS가 아니더라도 중요한 DB를 다룰 때에는 되도록 root 계정으로 접근하는 것보다는 권한이 제한된 일반 계정으로 접근하는 게 좋다.
MySQL에서 사용자 목록을 보려면 다음과 같은 명령어를 이용한다.
USE mysql;
SELECT * FROM user;혹은 DataGrip에서는, Server Objects → users 디렉토리 안에 유저 목록을 확인할 수 있다.

사용자 생성하기
-- CREATE USER '사용자명'@'접속위치' IDENTIFIED BY '비밀번호';
-- CREATE USER 'user_1'@'localhost' IDENTIFIED BY 'abcdefg';
-- CREATE USER 'user_1'@'12.345.678.90' IDENTIFIED BY 'abcdefg';
CREATE USER 'user_1'@'%' IDENTIFIED BY 'abcdefg';
사용자 삭제하기
DROP USER 'user_1'@'%';2. 권한
-- 사용자에 권한 추가
GRANT SELECT ON mydatabase.businesses
TO 'user_1'@'%';
GRANT UPDATE, DELETE ON mydatabase.businesses
TO 'user_1'@'%';-- 사용자 권한 조회
SHOW GRANTS FOR 'user_1'@'%';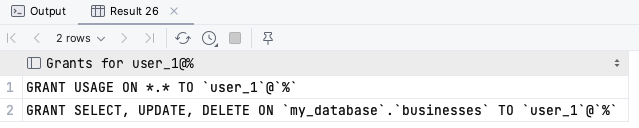
-- 데이터베이스의 모든 권한 부여
GRANT ALL PRIVILEGES ON mydatabase.*
TO 'user_1'@'%';