

본 글은 갖고노는 MySQL 데이터베이스 by 얄코 강의를 수강하고 이를 정리한 글입니다.
SELECT 심화, 복합적인 데이터 가져오기
1. 서브 쿼리(Sub Query)
서브 쿼리는 쿼리 안에 들어가있는 또다른 쿼리를 말한다.
1. 비상관 서브 쿼리
메인 쿼리 문과 서브 쿼리 문이 서로 관계가 없는 것, 테이블을 서로 참조하지 아니하는 것
SELECT
CategoryID, CategoryName, Description,
(SELECT ProductName FROM Products WHERE ProductID = 1)
FROM Categories;
-- Categories 내에서, ProductID = 1인 ProductName을 Products에서 뽑아냄| CategoryID | CategoryName | Description | (SELECT ProductName FROM Products WHERE ProductID = 1) |
|---|---|---|---|
| 1 | Beverages | Soft drinks, coffees, teas, beers, and ales | Chais |
| 2 | Condiments | Sweet and savory sauces, relishes, spreads, and seasonings | Chais |
SELECT AVG(Price) FROM Products -- 28.866364SELECT * FROM Products
WHERE Price < (
SELECT AVG(Price) FROM Products
);
-- 28.866364보다 작은 Price를 갖는 Products만 출력됨| ProductID | ProductName | SupplierID | CategoryID | Unit | Price |
|---|---|---|---|---|---|
| 1 | Chais | 1 | 1 | 10 boxes x 20 bags | 18.00 |
| 2 | Chang | 1 | 1 | 24 - 12 oz bottles | 19.00 |
| 3 | Aniseed Syrup | 1 | 2 | 12 - 550 ml bottles | 10.00 |
SELECT
CategoryID, CategoryName, Description
FROM Categories
WHERE
CategoryID =
(SELECT CategoryID FROM Products
WHERE ProductName = 'Chais');
-- ProductName이 'Chais'인 Product 중에서 CategoryID가 같은 Category를 갖고 온다| CategoryID | CategoryName | Description |
|---|---|---|
| 1 | Beverages | Soft drinks, coffees, teas, beers, and ales |
SELECT
CategoryID, CategoryName, Description
FROM Categories
WHERE
CategoryID IN
(SELECT CategoryID FROM Products
WHERE Price > 50);
-- SELECT CategoryID FROM Products
-- WHERE Price > 50
-- 6, 8, 3, 6, 1, 7, 4| CategoryID | CategoryName | Description |
|---|---|---|
| 1 | Beverages | Soft drinks, coffees, teas, beers, and ales |
| 3 | Confections | Desserts, candies, and sweet breads |
| 4 | Dairy Products | Cheeses |
| 6 | Meat/Poultry | Prepared meats |
| 7 | Produce | Dried fruit and bean curd |
| 8 | Seafood | Seaweed and fish |
| 연산자 | 의미 |
|---|---|
| ~ ALL | 서브쿼리의 모든 결과에 대해 ~하다 |
| ~ ANY | 서브쿼리의 하나 이상의 결과에 대해 ~하다 |
ALL: 모든 결과에 대해 비교
SELECT * FROM Products
WHERE Price > ALL (
SELECT Price FROM Products
WHERE CategoryID = 2
); -- Price 전체 중 무엇보다 더 큰, 즉 MAX(Price)에 대해서 큰 Product 선택SELECT MAX(Price) FROM Products
WHERE CategoryID = 2
-- 43.90| ProductID | ProductName | SupplierID | CategoryID | Unit | Price |
|---|---|---|---|---|---|
| 9 | Mishi Kobe Niku | 4 | 6 | 18 - 500 g pkgs. | 97.00 |
| 18 | Carnarvon Tigers | 7 | 8 | 16 kg pkg. | 62.50 |
| 20 | Sir Rodney's Marmalade | 8 | 3 | 30 gift boxes | 81.00 |
ANY: 하나 이상의 결과만 만족하면 됨, 대충 IN 으로도 사용할 수 있음
아래 두 코드는 같은 의미를 가짐
SELECT
CategoryID, CategoryName, Description
FROM Categories
WHERE
CategoryID = ANY
(SELECT CategoryID FROM Products
WHERE Price > 50);SELECT
CategoryID, CategoryName, Description
FROM Categories
WHERE
CategoryID IN
(SELECT CategoryID FROM Products
WHERE Price > 50);| CategoryID | CategoryName | Description |
|---|---|---|
| 1 | Beverages | Soft drinks, coffees, teas, beers, and ales |
| 3 | Confections | Desserts, candies, and sweet breads |
| 4 | Dairy Products | Cheeses |
상관 서브 쿼리
메인 쿼리와 서브 쿼리가 서로 맞물려 돌아간다.
이때 각각의 테이블 명칭을 지정해주어야 한다.
JOIN 이라는 기능을 더 많이 사용하긴 하지만, 그래도 상관 서브 쿼리 역시 알아두어야 할 필요는 있다.
SELECT
ProductID, ProductName,
(
SELECT CategoryName FROM Categories C
WHERE C.CategoryID = P.CategoryID
-- C의 CategoryID와 P의 CategoryID가 같은 상품을 조회한다.
-- 이렇게 하는 이유는 Products가 FK로 CategoryID를 갖기 때문이다
) AS CategoryName
FROM Products P;| ProductID | ProductName | CategoryName |
|---|---|---|
| 1 | Chais | Beverages |
| 2 | Chang | Beverages |
| 3 | Aniseed Syrup | Condiments |
SELECT
SupplierName, Country, City,
(
SELECT COUNT(*) FROM Customers C
WHERE C.Country = S.Country
) AS CustomersInTheCountry,
(
SELECT COUNT(*) FROM Customers C
WHERE C.Country = S.Country
AND C.City = S.City
) AS CustomersInTheCity
FROM Suppliers S;| SupplierName | Country | City | CustomersInTheCountry | CustomersInTheCity |
|---|---|---|---|---|
| Exotic Liquid | UK | Londona | 7 | 0 |
| New Orleans Cajun Delights | USA | New Orleans | 13 | 0 |
| Grandma Kelly's Homestead | USA | Ann Arbor | 13 | 0 |
Suppliers S 테이블에서 Country를 FK로 Customers 테이블에 접근한다.
Country가 일치하는 Customers C의 개수, 그리고 Country와 City가 모두 일치하는 Customers C의 개수를 찾는다.
SELECT
CategoryID, CategoryName,
(
SELECT MAX(Price) FROM Products P
WHERE P.CategoryID = C.CategoryID
) AS MaximumPrice,
(
SELECT AVG(Price) FROM Products P
WHERE P.CategoryID = C.CategoryID
) AS AveragePrice
FROM Categories C;| CategoryID | CategoryName | MaximumPrice | AveragePrice |
|---|---|---|---|
| 1 | Beverages | 263.50 | 37.979167 |
| 2 | Condiments | 43.90 | 23.062500 |
Categories C로부터 외래키를 갖고 온다. 먼저 CategoryID를 FK로 Products 테이블에서 Max Price를 갖고 온다. 또한 FK로 Products 테이블에서 AVG Price 값도 가져온다.
아래는 같은 테이블에서 또다른 서브 쿼리를 가져오는 예시이다.
SELECT
ProductID, ProductName, CategoryID, Price
-- ,(SELECT AVG(Price) FROM Products P2
-- WHERE P2.CategoryID = P1.CategoryID) AS Avg
FROM Products P1
WHERE Price < (
SELECT AVG(Price) FROM Products P2
WHERE P2.CategoryID = P1.CategoryID
);| ProductID | ProductName | CategoryID | Price |
|---|---|---|---|
| 1 | Chais | 1 | 18.00 |
| 2 | Chang | 1 | 19.00 |
P2 제품 중에서 평균 가격이 낮은 제품들만 가져옴(저가 제품)
주석을 풀면 평균가를 확인할 수도 있음.
| ProductID | ProductName | CategoryID | Price | Avg |
|---|---|---|---|---|
| 1 | Chais | 1 | 18.00 | 37.979167 |
| 2 | Chang | 1 | 19.00 | 37.979167 |
| 3 | Aniseed Syrup | 2 | 10.00 | 23.062500 |
NOT / NOT EXISTS 연산자
SELECT
CategoryID, CategoryName
-- ,(SELECT MAX(P.Price) FROM Products P
-- WHERE P.CategoryID = C.CategoryID
-- ) AS MaxPrice
FROM Categories C
WHERE EXISTS (
SELECT * FROM Products P
WHERE P.CategoryID = C.CategoryID
AND P.Price > 80
);카테고리에 해당하는 제품군 중에서 가격이 80이 넘는 제품군만 가져온다.
이때 SELECT * FROM Products P WHERE P.CategoryID = C.CategoryID AND P.Price > 80 가 존재할 때만 Categories C에서 CategoryID와 CategoryName을 가져온다.
주석을 풀고 표를 보면 아래와 같이 나온다.
| CategoryID | CategoryName | MaxPrice |
|---|---|---|
| 1 | Beverages | 263.50 |
| 3 | Confections | 81.00 |
| 6 | Meat/Poultry | 123.79 |
2. JOIN - 여러 테이블 가져오기
내부 JOIN
JOIN은 SQL에서 가장 중요한 문법이다. RDBMS에서는 중복을 제거하고 의존성을 낮추기 위해서 여러 정규화를 하게 되는데, 이때 나누어진 테이블을 다시 합치는 과정이 바로 JOIN이라고 할 수 있다.
SELECT * FROM Categories C
JOIN Products P
ON C.CategoryID = P.CategoryID;| CategoryID | CategoryName | Description | ProductID | ProductName | SupplierID | CategoryID | Unit | Price |
|---|---|---|---|---|---|---|---|---|
| 1 | Beverages | Soft drinks, coffees, teas, beers, and ales | 1 | Chais | 1 | 1 | 10 boxes x 20 bags | 18.00 |
| 1 | Beverages | Soft drinks, coffees, teas, beers, and ales | 2 | Chang | 1 | 1 | 24 - 12 oz bottles | 19.00 |
| 2 | Condiments | Sweet and savory sauces, relishes, spreads, and seasonings | 3 | Aniseed Syrup | 1 | 2 | 12 - 550 ml bottles | 10.00 |
| 2 | Condiments | Sweet and savory sauces, relishes, spreads, and seasonings | 4 | Chef Anton's Cajun Seasoning | 2 | 2 | 48 - 6 oz jars | 22.00 |
| 2 | Condiments | Sweet and savory sauces, relishes, spreads, and seasonings | 5 | Chef Anton's Gumbo Mix | 2 | 2 | 36 boxes | 21.35 |
| 2 | Condiments | Sweet and savory sauces, relishes, spreads, and seasonings | 6 | Grandma's Boysenberry Spread | 3 | 2 | 12 - 8 oz jars | 25.00 |
보면 알겠지만, CategoryName이 여러 곳에서 중복되는 것을 알 수 있다. 이를 방지하기 위해서 NF 정규화를 하게 되는데, 이를 다시 원하는 대로 합칠 때 JOIN을 쓰게 된다.
SELECT C.CategoryID, C.CategoryName, P.ProductName
FROM Categories C
JOIN Products P
ON C.CategoryID = P.CategoryID;
-- ambiguous 주의!
-- SELECT 명단 위에 C. P.을 제거해보자.
-- 다른 것은 문제가 안 되나, FK로 쓰이는 CategoryID에서 모호함이 발생한다.
-- 이는 같은 컬럼 이름을 가지는 P와 C의 카테고리 중 CategoryID 중 무엇을 선택하지 몰라서 발생하는 에러이다.SELECT
CONCAT(
P.ProductName, ' by ', S.SupplierName
) AS Product,
S.Phone, P.Price
FROM Products P
JOIN Suppliers S
ON P.SupplierID = S.SupplierID
WHERE Price > 50
ORDER BY ProductName;| Product | Phone | Price |
|---|---|---|
| Carnarvon Tigers by Pavlova, Ltd. | (03) 444-2343 | 62.50 |
| Côte de Blaye by Aux joyeux ecclésiastiques | (1) 03.83.00.68 | 263.50 |
| Manjimup Dried Apples by G'day, Mate | (02) 555-5914 | 53.00 |
| Mishi Kobe Niku by Tokyo Traders | (03) 3555-5011 | 97.00 |
여러 테이블 JOIN하기
아래와 같이 여러 테이블을 JOIN시킬 수 있다.
SELECT
C.CategoryID, C.CategoryName,
P.ProductName,
O.OrderDate,
D.Quantity
FROM Categories C
JOIN Products P
ON C.CategoryID = P.CategoryID
JOIN OrderDetails D
ON P.ProductID = D.ProductID
JOIN Orders O
ON O.OrderID = D.OrderID;| CategoryID | CategoryName | ProductName | OrderDate | Quantity |
|---|---|---|---|---|
| 4 | Dairy Products | Queso Cabrales | 1996-07-04 | 12 |
| 5 | Grains/Cereals | Singaporean Hokkien Fried Mee | 1996-07-04 | 10 |
| 4 | Dairy Products | Mozzarella di Giovanni | 1996-07-04 | 5 |
각각 Categories, Products, OrderDetails, Orders 테이블이 CategoryID, ProductID, OrderID를 FK로 JOIN된 것을 볼 수 있다.
한편 JOIN 한 테이블을 그룹화할 수 있다.
SELECT
C.CategoryName,
MIN(O.OrderDate) AS FirstOrder,
MAX(O.OrderDate) AS LastOrder,
SUM(D.Quantity) AS TotalQuantity
FROM Categories C
JOIN Products P
ON C.CategoryID = P.CategoryID
JOIN OrderDetails D
ON P.ProductID = D.ProductID
JOIN Orders O
ON O.OrderID = D.OrderID
GROUP BY C.CategoryID;
-- 각 카테고리마다 첫 번째 주문, 마지막 주문, 총 주문량 등을 알 수 있다.| CategoryName | FirstOrder | LastOrder | TotalQuantity |
|---|---|---|---|
| Beverages | 1996-07-10 | 1998-05-06 | 9532 |
| Condiments | 1996-07-08 | 1998-05-06 | 5298 |
| Confections | 1996-07-09 | 1998-05-06 | 7906 |
| Dairy Products | 1996-07-04 | 1998-05-06 | 9149 |
SELECT
C.CategoryName, P.ProductName,
MIN(O.OrderDate) AS FirstOrder,
MAX(O.OrderDate) AS LastOrder,
SUM(D.Quantity) AS TotalQuantity
FROM Categories C
JOIN Products P
ON C.CategoryID = P.CategoryID
JOIN OrderDetails D
ON P.ProductID = D.ProductID
JOIN Orders O
ON O.OrderID = D.OrderID
GROUP BY C.CategoryID, P.ProductID;
-- 이번에는 각 상품 별로 첫 주문, 마지막 주문, 총 주문량을 알 수 있다.| CategoryName | ProductName | FirstOrder | LastOrder | TotalQuantity |
|---|---|---|---|---|
| Beverages | Chais | 1996-08-20 | 1998-05-05 | 828 |
| Beverages | Chang | 1996-07-12 | 1998-05-06 | 1057 |
| Beverages | Guaraná Fantástica | 1996-07-11 | 1998-05-05 | 1125 |
| Beverages | Sasquatch Ale | 1996-08-22 | 1998-05-01 | 506 |
Self JOIN하기
같은 테이블을 대상으로 JOIN을 할 수 있다. 예를 들어서, ID 1번의 직원이 있고, 그 다음 ID 2 직원(nextEmployee)를 검색한다고 해보자.
SELECT
E1.EmployeeID, CONCAT_WS(' ', E1.FirstName, E1.LastName) AS Employee,
E2.EmployeeID, CONCAT_WS(' ', E2.FirstName, E2.LastName) AS NextEmployee
FROM Employees E1 JOIN Employees E2
ON E1.EmployeeID + 1 = E2.EmployeeID;
-- 1번의 전, 마지막 번호의 다음은?같은 Employees 테이블에 대해서 E1, E2를 JOIN하고, 대신 E1.EmployID + 1 에 해당하는 FK로 E2를 Self Join한다.
| EmployeeID | Employee | EmployeeID | NextEmployee |
|---|---|---|---|
| 1 | Nancy Davolio | 2 | Andrew Fuller |
| 2 | Andrew Fuller | 3 | Janet Leverling |
| 3 | Janet Leverling | 4 | Margaret Peacock |
| 4 | Margaret Peacock | 5 | Steven Buchanan |
| … | |||
| 8 | Laura Callahan | 9 | Anne Dodsworth |
다만 이 결과를 잘 살펴보면, NextEmployee가 1일 때 0번(NULL)의 Employee가 없고, 또 Employee가 9일 때 그 다음 NextEmployee(NULL)이 없다는 것을 알 수 있다. 이렇게 데이터의 양 끝단에 대해서 JOIN을 하려면, LEFT JOIN, RIGHT JOIN 등의 양 끝단에 대한 JOIN 이 필요하다.
LEFT , RIGHT외부 JOIN
- 반대쪽에 데이터가 있든 없든(NULL), 선택된 방향에 있으면 출력 - 행 수 결정
OUTER는 선택사항
위의 예시에서, LEFT JOIN 으로 쿼리를 바꾸면, 왼쪽에만 데이터가 있고 오른쪽에 NULL이 들어와도 결과를 보여준다.
SELECT
E1.EmployeeID, CONCAT_WS(' ', E1.FirstName, E1.LastName) AS Employee,
E2.EmployeeID, CONCAT_WS(' ', E2.FirstName, E2.LastName) AS NextEmployee
FROM Employees E1
LEFT JOIN Employees E2
ON E1.EmployeeID + 1 = E2.EmployeeID
ORDER BY E1.EmployeeID;| EmployeeID | Employee | EmployeeID | NextEmployee |
|---|---|---|---|
| 1 | Nancy Davolio | 2 | Andrew Fuller |
| 2 | Andrew Fuller | 3 | Janet Leverling |
| … | |||
| 9 | Anne Dodsworth |
반대로 RIGHT JOIN 으로 바꾸어보면, 이번에는 오른쪽에만 값이 있고 왼쪽에 NULL 이 들어와도 결과를 보여준다.
| EmployeeID | Employee | EmployeeID | NextEmployee |
|---|---|---|---|
| 1 | Nancy Davolio | ||
| 1 | Nancy Davolio | 2 | Andrew Fuller |
| 2 | Andrew Fuller | 3 | Janet Leverling |
| … | |||
| 8 | Laura Callahan | 9 | Anne Dodsworth |
아래 예시에서는 IFNULL 함수를 이용해서, CustomerName이 없다면 -- NO CUSTOMER -- 를 출력하도록 한 예시이다.
SELECT
IFNULL(C.CustomerName, '-- NO CUSTOMER --'),
IFNULL(S.SupplierName, '-- NO SUPPLIER --'),
IFNULL(C.City, S.City),
IFNULL(C.Country, S.Country)
FROM Customers C
**LEFT JOIN** Suppliers S
ON C.City = S.City AND C.Country = S.Country;| IFNULL(C.CustomerName, '-- NO CUSTOMER --') | IFNULL(S.SupplierName, '-- NO SUPPLIER --') | IFNULL(C.City, S.City) | IFNULL(C.Country, S.Country) |
|---|---|---|---|
| Paris spécialités | Aux joyeux ecclésiastiques | Paris | France |
| Spécialités du monde | Aux joyeux ecclésiastiques | Paris | France |
| Mère Paillarde | Ma Maison | Montréal | Canada |
| Ana Trujillo Emparedados y helados | -- NO SUPPLIER -- | México D.F. | Mexico |
| Antonio Moreno Taquería | -- NO SUPPLIER -- | México D.F. | Mexico |
| Around the Horn | -- NO SUPPLIER -- | London | UK |
이번에는 RIGHT JOIN 을 이용해보자.
SELECT
IFNULL(C.CustomerName, '-- NO CUSTOMER --'),
IFNULL(S.SupplierName, '-- NO SUPPLIER --'),
IFNULL(C.City, S.City),
IFNULL(C.Country, S.Country)
FROM Customers C
RIGHT JOIN Suppliers S
ON C.City = S.City AND C.Country = S.Country;| IFNULL(C.CustomerName, '-- NO CUSTOMER --') | IFNULL(S.SupplierName, '-- NO SUPPLIER --') | IFNULL(C.City, S.City) | IFNULL(C.Country, S.Country) |
|---|---|---|---|
| Queen Cozinha | Refrescos Americanas LTDA | São Paulo | Brazil |
| Spécialités du monde | Aux joyeux ecclésiastiques | Paris | France |
| Tradição Hipermercados | Refrescos Americanas LTDA | São Paulo | Brazil |
| -- NO CUSTOMER -- | Exotic Liquid | Londona | UK |
| -- NO CUSTOMER -- | New Orleans Cajun Delights | New Orleans | USA |
3. UNION - 집합으로 다루기
UNION 은 컬럼을 기준으로 테이블을 합치는 JOIN과 달리, 행(ROW)을 기준으로 테이블을 합친다. 자주 안 쓰이는 것 같으나, 필요할 때 찾아서 사용하면 좋을 것 같다.
| 연산자 | 설명 |
|---|---|
| UNION | 중복을 제거한 집합 |
| UNION ALL | 중복을 제거하지 않은 집합 |
SELECT CustomerName AS Name, City, Country, 'CUSTOMER'
FROM Customers
UNION
SELECT SupplierName AS Name, City, Country, 'SUPPLIER'
FROM Suppliers
ORDER BY Name;각 Customers와 Suppliers 테이블에서 같은 컬럼 명을 가진 City, Country, 그리고 다른 컬럼명이긴 하나 CustomerName과 SupplierName을 Name이라는 하나의 컬럼명으로 합친다. 그리고 Customers에서 뽑아온 행은 ‘CUSTOMER’, Suppliers에서 뽑아온 행은 ‘SUPPLIER’라고 이름을 붙인다.
| Name | City | Country | CUSTOMER |
|---|---|---|---|
| Alfreds Futterkiste | Berlin | Germany | CUSTOMER |
| Ana Trujillo Emparedados y helados | México D.F. | Mexico | CUSTOMER |
| Antonio Moreno Taquería | México D.F. | Mexico | CUSTOMER |
| Around the Horn | London | UK | CUSTOMER |
| Aux joyeux ecclésiastiques | Paris | France | SUPPLIER |
합집합

SELECT CategoryID AS ID FROM Categories
WHERE CategoryID > 4
UNION
SELECT EmployeeID AS ID FROM Employees
WHERE EmployeeID % 2 = 0;
-- CategoryID가 4 이사인 것과, EmployeeID가 짝수인 것을 합친다| ID |
|---|
| 5 |
| 6 |
| 7 |
| 8 |
| 2 |
| 4 |
위 결과를 UNION ALL 로 바꾸면, 중복된 요소 역시 전부 갖고 온다.
SELECT CategoryID AS ID FROM Categories
WHERE CategoryID > 4
UNION
SELECT EmployeeID AS ID FROM Employees
WHERE EmployeeID % 2 = 0;
-- CategoryID가 4 이상인 것과, EmployeeID가 짝수인 것을 중복 허용해서 합친다| ID |
|---|
| 5 |
| 6 |
| 7 |
| 8 |
| 2 |
| 4 |
| 6 |
| 8 |
교집합
SELECT CategoryID AS ID
FROM Categories C, Employees E
WHERE
C.CategoryID > 4
AND E.EmployeeID % 2 = 0
AND C.CategoryID = E.EmployeeID;| ID |
|---|
| 6 |
| 8 |
UNION 대신, AND 연산을 사용했고, Categories와 Employees 테이블에 복합적으로 ID를 가져온다.
차집합
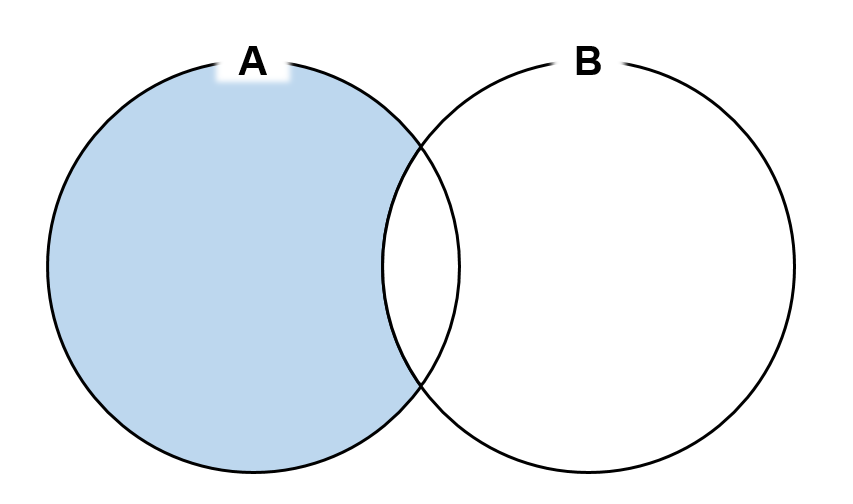
SELECT CategoryID AS ID
FROM Categories
WHERE
CategoryID > 4
AND CategoryID NOT IN (
SELECT EmployeeID
FROM Employees
WHERE EmployeeID % 2 = 0
);| ID |
|---|
| 5 |
| 7 |
NOT IN을 사용해서 차집합 이용
대칭차집합

사실 대칭차집합을 만드는 방법은 여러 가지가 있다. 강의에서는 중복되지 않는, 즉 COUNT가 1인 원소만 가져오는 방식으로 대칭 차집합을 완성했다. 그 외에도 중복되는 것을 제외하는 방식, 드 모르간 법칙을 이용해서 다양하게 논리식을 조합하는 방식을 이용할 수 있다.
SELECT ID FROM (
SELECT CategoryID AS ID FROM Categories
WHERE CategoryID > 4
UNION ALL
SELECT EmployeeID AS ID FROM Employees
WHERE EmployeeID % 2 = 0
) AS Temp
GROUP BY ID HAVING COUNT(*) = 1;| ID |
|---|
| 2 |
| 4 |
| 5 |
| 7 |