

vector와 list 중 무엇을 써야 할까?
결론부터 말하면 거의 대부분의 상황에서 그냥 std::vector를 쓰면 된다.
그 이유를 알면 더 좋다.
std::vector와 std::list의 차이
C++에서는 배열로 사용할 수 있는 컨테이너를 여러 개 지원하는데, 그 중 가장 많이 쓰이는 것은 std::vector와 std::list가 있다. 두 개 다 역할은 비슷한 거 같은데, 그 내부 구현은 완전히 다르다.
먼저 std::vector는, 그 내부 구조가 연속적인(Sequential 타입) 배열 형태로 이루어져 있다. 실제 물리적인 메모리 구조 상으로 연속적인 구조이다.

위 그림 모델이 정확히 std::vector의 모습을 표현하고 있다.
반면에 std::list는, 내부가 불연속적인(Non-sequential 타입) 형태이다. 자료구조를 배웠으면 '더블 링크드 리스트'를 들어봤을 것이다. std::list는 내부 구현이 더블 링크드 리스트로 되어 있다.

벡터(배열) VS 리스트
이 글은 더블 링크드 리스트를 안다고 전제하고 설명을 이어간다.
그런데 우리가 자료구조를 배울 때 더블 링크드 리스트와 배열의 차이점에 대해서 배울 때 그 시간 복잡도에 대해 다음과 같이 배운다.
| search | insertion | deletion | |
|---|---|---|---|
| Linked List | O(n) | O(1) | O(1) |
| vector(array) | O(n) | O(n) | O(n) |
이 표를 보면, 벡터(배열)과 링크드 리스트는 탐색(Search)에 O(n), 그리고 삽입과 삭제에 대해서 벡터는 O(n)의 시간이 필요한 반면 더블 링크드 리스트는 O(1)의 시간이 필요하다고 되어 있다.
벡터는 원소를 하나 삭제하면, 그 뒤에 있는 n개 원소를 앞으로 이동시키는 연산이 추가적으로 필요하기 때문이다. 그래서 O(n)의 시간이 걸린다. 반면 링크드 리스트는 연결된 포인터(참조)를 끊는 연산만 진행하면 되기 때문에 O(1)의 시간이 걸린다.
삽입도 마찬가지다. 벡터는 i번 째 위치에 원소를 삽입하려면 기존 i번을 i+1번으로, 등등 해서 n개 원소를 뒤로 미는 연산을 진행하기 때문에 O(n)의 시간이 걸린다. 반면 링크드 리스트는 그냥 포인터만 연결하면 된다.
이렇게만 보면 당연히 링크드 리스트를 이용하는게 더 좋아보인다. 그럼 왜 이 좋은 링크드 리스트를 이용하면 되지 배열을 사용하는 것일까?
실제 컴퓨터 환경에서는 물리적인 제약 때문에 저 이론에 수정이 필요하기 때문이다. 이제 이 물리적인 제약으로 인한 사항을 토대로 Search, Insertion, Deletion에 대해 벡터가 리스트보다 좋다는 것을 주장하겠다.
Search
물리적인 제약이란 CPU의 메모리 계층 구조때문이다.
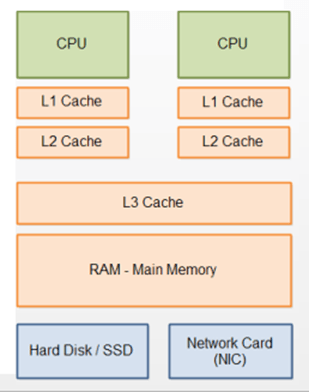
CPU의 레지스터는 메모리의 순차적인 읽기/쓰기가 가장 빠르다. 그 이유는 캐시 메모리의 크기가 RAM보다 훨씬 작아서, 보통 메모리를 읽어들일 때 한 메모리 청크 단위로 읽기 때문이다.
만약 한 청크 안에 읽고자 하는 메모리 A, B가 있으면 이 둘을 읽는데 걸리는 시간은 매우 짧다. 만약 A, B가 물리적으로 멀리 떨어져 있어 한 청크 안에 담겨있지 않을 경우, A를 읽은 후, B를 찾기 위해 CPU는 L1, L2, L3 캐시 등에서 차례로 B의 메모리 영역을 요청한다. 최악의 경우 L3에도 없으면 DRAM에서 찾아야 한다. I/O 단계에서 이 과정이 꽤 많은 오버헤드를 발생시킨다.
캐시 메모리로 인한 오버헤드를 주제로 포스팅한 다른 글이 있는데, 여기 첨부하겠다. 읽어보면 도움이 된다.
이게 벡터와 링크드 리스트의 성능을 결정짓는데 매우 중요한 역할을 한다.
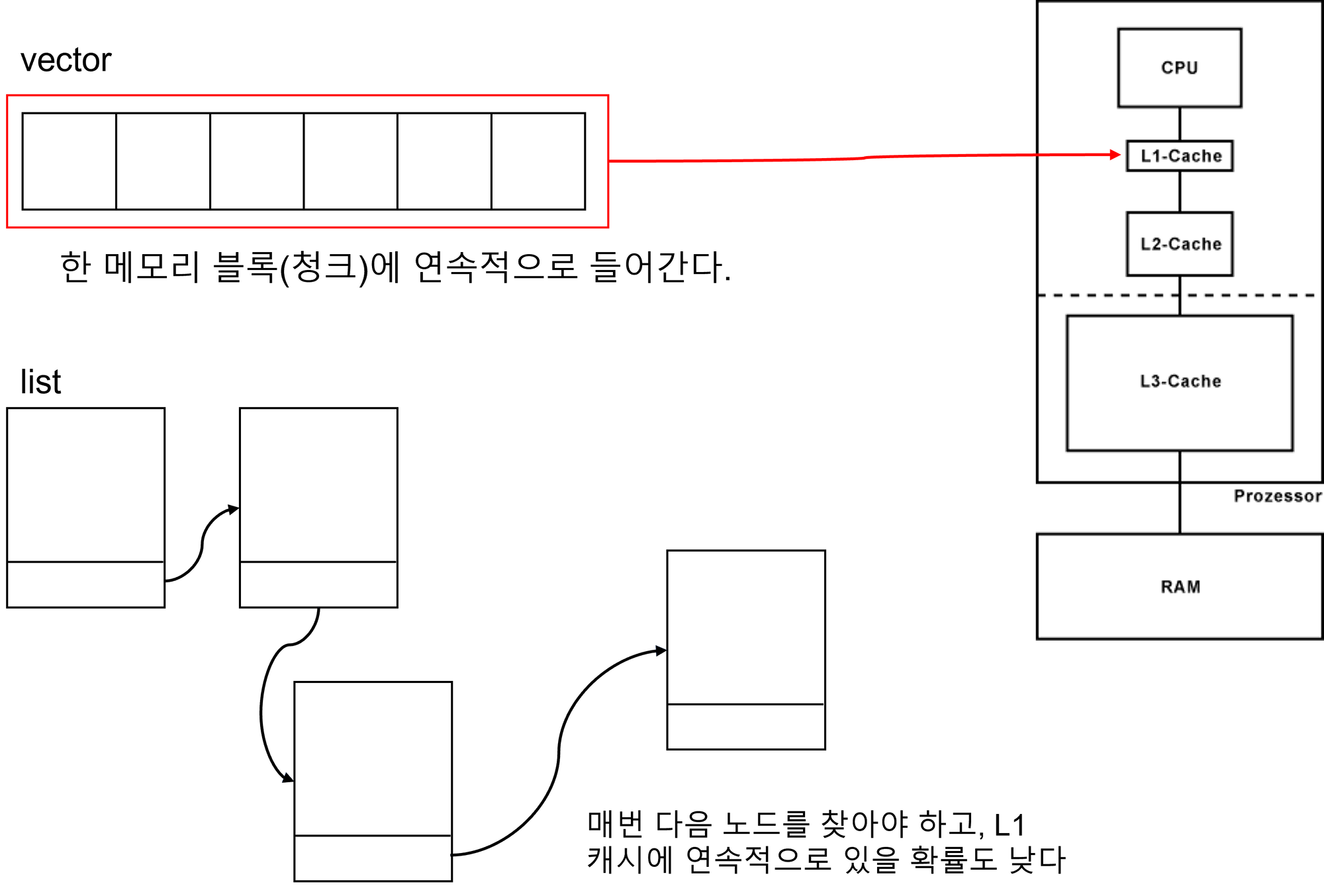
벡터의 경우 물리적으로 메모리 블록이 연속적으로 위치해있기에, 순차 읽기를 하는데 있어서 메모리 블록이 한 청크에 담겨 있을 확률이 높다.
반면에 더블 링크드 리스트의 경우, 메모리 위치가 불연속적이다. 애초에 어디에 존재할 지 알 수가 없다. 보통 운영체제가 상황에 맞추어서 가장 가까운 위치에 배정해주기는 하는데, 이것도 이상적인 경우지 잘못하면 한 노드에서 다른 노드로 가는데 L1, L2, L3에도 없으면 RAM에서 읽어야 한다. 그렇기 때문에 탐색의 시간 복잡도가 같은 O(n)이라 하더라도 배열과 리스트는 그 탐색 성능이 어마어마하게 다를 수 밖에 없다.
Insertion
삽입의 경우, 애초에 벡터에서 삽입에 O(n)의 시간이 걸린다는 것은 함정이 숨어 있다. 바로 뒤에 n개 원소가 있을 때 이를 뒤로 밀어야 하기 때문에 O(n)의 시간이 걸린다는 것이었는데, 생각해보면 우리가 보통 벡터를 쓸 때 원소를 맨 뒤에 추가하는 경우가 대부분이지 앞이나 중간에 무언가를 추가하는 일은 잘 없다. push_back이나 emplace_back 등을 통해 맨 뒤에 원소를 추가할 경우 벡터도 마찬가지로 O(1)의 시간이 걸린다.
따라서 Insertion 역시 O(1)으로 퉁칠 수 있다.
Deletion
삭제의 경우는 약간의 트릭이 필요한데, 중간에 있는 원소를 삭제한다고 해도 뒤에 있는 원소들을 모두 앞으로 땡길 필요까진 없다. 약간의 트릭을 쓰면 된다.
std::vector<int> v = {0, 1, 2, 3, 4, 5};6개의 원소가 들어있는 벡터 v에서, 우리가 2를 삭제하고 싶다고 가정하자. 그러면 2를 삭제하고 뒤에 있는 3, 4, 5를 앞으로 모두 밀어야 할까? 아니다. 바로 맨 뒤에 있는 5를 2로 대체하면 된다!
그러면
{0, 1, 5, 3, 4}이런 식으로 만들면 된다. 그러면 2는 5와 자리를 옮긴다고 생각하면 편하고, 이렇게 맨 뒤에 있는 원소로 삭제하려는 대상 원소를 대체한다고 했을 시 똑같이 O(1)의 시간이 걸린다.
물론 원소들의 '순서'가 중요하다면 이야기는 달라질 수 있다. 그러나 굳이 삭제 후에 원소의 순서가 중요한 게 아니라면, 삭제 역시 O(1)으로 퉁칠 수 있다.
결론
Insertion과 Deletion에서의 성능이 O(1)이라면, 탐색 성능에서 훨씬 성능이 좋은 벡터를 쓰지 않을 이유가 없다. 그래서 대부분의 경우에 벡터를 쓰면 된다고 하는 것이다.
물론 예외적인 상황도 있다. 중간에 삽입하는 연산이 매우 빈번하게 일어나는 경우, 혹은 삭제 후에도 원소의 순서를 유지해야 하고, 또 삭제 연산이 매우 빈번하게 일어나서, 이 탐색에 대한 성능을 포기해서라도 링크드 리스트를 쓰는게 더 효과적인 경우에는 std::list를 써도 된다. 그러나 대부분의 경우는 std::vector를 쓰게 될 것이다. 왜냐면 사실 Search가 가장 많이 쓰이는 행동이고 엥간하면 이 연산이 프로그램의 성능을 결정짓는 연산이 되는 경우가 많기 때문이다.
실제 성능 측정
번외로 실제로 탐색 성능에 있어서 얼마나 큰 차이를 보이는 지 알아보자.
코드는 아래와 같다.
#include <iostream>
#include <vector>
#include <list>
#include <thread>
#include <chrono>
class vectorManager
{
public:
vectorManager() = default;
~vectorManager() = default;
auto insertion(const std::size_t max) {
v.reserve(max);
for (std::size_t i = 0; i < max; ++i) {
v.emplace_back(i);
}
}
auto read() {
auto start = std::chrono::high_resolution_clock::now();
auto sum = 0;
for (const auto& i : v) {
sum = i;
}
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> elapsed = end - start;
return elapsed.count();
}
private:
std::vector<int> v;
};
class listManager
{
public:
listManager() = default;
~listManager() = default;
auto insertion(const std::size_t max) {
for (std::size_t i = 0; i < max; ++i) {
l.emplace_back(i);
}
}
auto read() {
auto start = std::chrono::high_resolution_clock::now();
int sum = 0;
for (const auto& i : l) {
sum = i;
}
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> elapsed = end - start;
return elapsed.count();
}
private:
std::list<int> l;
};
int main()
{
vectorManager vm;
listManager lm;
constexpr auto testTime = 10;
vm.insertion(1'000'000'000);
lm.insertion(1'000'000'000);
double sumTime_v = 0;
double sumTime_l = 0;
for (int i = 0; i < testTime; ++i) {
std::jthread t1([&]() {
auto readtime = vm.read();
std::cout << "vector read time: " << readtime << "s" << std::endl;
sumTime_v += readtime;
});
std::jthread t2([&]() {
auto readtime = lm.read();
std::cout << "list read time: " << readtime << "s" << std::endl;
sumTime_l += readtime;
});
}
auto avgTime_v = sumTime_v / testTime;
auto avgTime_l = sumTime_l / testTime;
std::cout << "vector average read time: " << avgTime_v << "s" << std::endl;
std::cout << "list average read time: " << avgTime_l << "s" << std::endl;
return 0;
}Output:
vector read time: 14.2727s
list read time: 45.2456s
vector read time: 23.0088s
list read time: 58.8445s
vector read time: 23.2634s
list read time: 59.5885s
vector read time: 23.0646s
list read time: 59.8489s
vector read time: 23.4892s
list read time: 60.1247s
vector read time: 23.2736s
list read time: 60.3862s
vector read time: 23.4284s
list read time: 60.1991s
vector read time: 23.9611s
list read time: 60.9885s
vector read time: 23.6419s
list read time: 61.1249s
vector read time: 23.8847s
list read time: 61.0446s
vector average read time: 22.5288s
list average read time: 58.7395s10번 정도 반복해서 돌렸을 때, vector의 원소 읽기는 23초 정도가 걸리고, 연결 리스트는 59초 정도가 걸린다. 2.6배나 차이가 난다.
환경에 따라서 절대 수치는 달라질 수 있다. 이 테스트 환경은 애플의 M1 Pro 8코어 CPU, 16GB 램이 탑재된 M1 맥북 프로 14" 상에서의 결과다. 하지만 벡터가 리스트보다 더 우수한 성능을 지닌다는 것만 확인하면 된다.